En mi oficina, tengo una vieja laptop a la cual, el monitor de cuando en cuando deja de funcionar sin forma de volver a encenderlo nuevamente. Con ello en consideración, decidí tomar esta laptop para configurarme un modesto servidor conUbuntu Server 14.04 LTS en el cual tengo habilitado Apache, PHP y MySQL principalmente con la cual te mostraré cómo conigurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu.
Es pertinente comentar en este que punto que para el presente tutorial, procedí a realizar una instalación limpia de Ubuntu Server 14.04, configuré mi tarjeta de red, particiones y demás, pero al concluir el proceso de reinicio posterior a la instalación.
Así, para lograr que Ubuntu “inicie” y se “conecte” automáticamente a una red WPA, tenemos que seguir los siguientes pasos desde la consola o línea de comandos:
1.- Averiguamos en primer lugar el nombre de nuestra interface de red inalámbrica (generalmente es wlan0):
iwconfig
2.- Creamos el archivo de configuración del demonio de administración de redes wpa_supplicant…
sudo nano /etc/wpa_supplicant/wpa_supplicant.conf
…y guardamos dentro del mismo los siguientes valores:
5.- Pedimos ahora una dirección IP al servidor DHCP activo:
sudo dhclient wlan0
6.- Con ello, si hacemos un ping a google.com, deberías de obtener ya una respuesta. Pero bien, para que nuestra configuración se cargue en cada reinicio, abrimos el archivo /etc/network/interfaces…
sudo nano /etc/network/interfaces
…y nos aseguramos de añadir lo siguiente:
auto wlan0
iface wlan0 inet dhcp
wpa-ssid NOMBRE-DE-RED-WIFI
wpa-psk CONTRASEÑA-WIFI
7.- Para comprobar que el demonio wpa_supplicant se iniciará automáticamente en cada inicio del sistema, ejecutamos los siguientes comandos:
Para todos aquellos que en algún momento tengan la necesidad de desarrollar actividades de administración de un servidor Web bajo GNU/Linux, descubrirán que Internet es un entorno más que propicio tanto para la colaboración o distribución de contenidos, como también, para prácticas maliciosas o ataques informáticos por lo que seguramente te resultará de gran utilidad el aprender a bloquear accesos por país con firewall CSF.
En este sentido, les comento que en mi práctica profesional, y concretamente, para el caso de una tienda en línea administrada con Magento, comencé a notar una baja en el performance impresionante, al punto tal en que las peticiones al servidor, se resolvían muy lentamente.
En este contexto, una solución “rápida” y “lógica” era incrementar los recursos del VPS contratado (más memoria RAM, más procesador), con el respectivo costo asociado.
Al revisar los logs de Apache (siempre es una buena práctica, algo tediosa) y las estadísticas del sitio en mi panel de control (con AW Stats o Webanalizer) y las visitas de Google Analytics, descubrí que tenía visitas en varias horas del día, y con distinta intensidad, del robot del buscador Chino llamado Baidu.
Con esta información en consideración, mi primer “movimiento” lógico, fue deshabilitar la indexación del agente/bot Baidu en el home de mi servidor, pero, el problema persistía: Baidu maneja diversos agentes (de contenidos, de imágenes, de video, etc.) para indexar un sitio, y para serles francos, aún y cuando Baidu tiene documentadas las medidas para el manejo de sus bots mediante el archivo robots.txt (puedes consultarlas aquí: http://help.baidu.com/question?prod_en=master&class=498&id=1000973), me dio la impresión de que sus bots no respetaban las instrucciones contenidas en el mismo, por lo cual, teniendo en consideración que el público de la tienda en línea era solo mexicano, procedí a realizar un bloqueo mediante reglas de un Firewall basado en software, inicialmente a China, con posibilidades de extenderlo a todo el mundo y permitir solo IP´s de México y Estados Unidos. Es importante destacar que Baidu, tiene una “página” en la cual uno puede “retroalimentar” y reportar incidentes; la liga es: http://webmaster.baidu.com/feedback/index. Aquí puedes encontrar más información sobre el “bloqueo” a Baidu Spider mediante el archivo robots.txt: http://www.baidu.com/search/robots_english.html
Consideraciones
Este “truco” te funcionará si tienes una distribución Linux en la cual tengas acceso como root o usuario con privilegios. Si tienes un VPS, asegúrate que si realizas por accidente un “bloqueo” a la IP desde la cual te conectas, podrás acceder nuevamente mediante una terminal o consola Web que te ofrezca tu propio proveedor.
Primeros pasos
CSF (ConfigServer Security & Firewall), es un poderoso conjunto de scripts que nos permiten disponer reglas de iptables para constituir un Firewall SPI (Stateful Packet Inspection) basado en software, con detector de intrusiones y seguridad en aplicaciones para servidores Linux.
Si actualmente tienes reglas de IPtables aplicadas en tu server, es muy probable que vayas a tener conflicto con las mismas, por lo cual, es muy probable que decidas qué solución de Firewall pretendes usar, o bien, analizar si CSF puede hacer por tí lo que actualmente estás haciendo con otra solución. Desde mi punto de vista personal, CSF es uno de los Firewalls para servidores Linux más potentes, transparentes y sencillos de usar que he visto.
Posteriormente, vamos a proceder a descargar y descomprimir el conjunto de scripts de CSF mediante el siguiente comando:
cd /usr/src
sudo wget https://download.configserver.com/csf.tgz
sudo tar -xzf csf.tgz
Ahora, procedemos a realizar la ejecución del script de instalación de CSF:
cd csf
sudo sh install.sh
Si no ha habido mayores problemas, podrás leer en tu pantalla algo como esto:
TCP ports currently listening for incoming connections:
22
UDP ports currently listening for incoming connections:
68,45861
Note: The port details above are for information only, csf hasn't been auto-configured.
Don't forget to:
1. Configure the following options in the csf configuration to suite your server: TCP_*, UDP_*
2. Restart csf and lfd
3. Set TESTING to 0 once you're happy with the firewall, lfd will not run until you do so
«lfd.sh» -> «/etc/init.d/lfd»
«csf.sh» -> «/etc/init.d/csf»
el modo de «/etc/init.d/lfd» permanece como 0755 (rwxr-xr-x)
el modo de «/etc/init.d/csf» permanece como 0755 (rwxr-xr-x)
Removing any system startup links for /etc/init.d/lfd ...
Removing any system startup links for /etc/init.d/csf ...
Adding system startup for /etc/init.d/lfd ...
/etc/rc0.d/K20lfd -> ../init.d/lfd
/etc/rc1.d/K20lfd -> ../init.d/lfd
/etc/rc6.d/K20lfd -> ../init.d/lfd
/etc/rc2.d/S80lfd -> ../init.d/lfd
/etc/rc3.d/S80lfd -> ../init.d/lfd
/etc/rc4.d/S80lfd -> ../init.d/lfd
/etc/rc5.d/S80lfd -> ../init.d/lfd
Adding system startup for /etc/init.d/csf ...
/etc/rc0.d/K80csf -> ../init.d/csf
/etc/rc1.d/K80csf -> ../init.d/csf
/etc/rc6.d/K80csf -> ../init.d/csf
/etc/rc2.d/S20csf -> ../init.d/csf
/etc/rc3.d/S20csf -> ../init.d/csf
/etc/rc4.d/S20csf -> ../init.d/csf
/etc/rc5.d/S20csf -> ../init.d/csf
«/etc/csf/csfwebmin.tgz» -> «/usr/local/csf/csfwebmin.tgz»
Installation Completed
Lo que debemos saber
CSF es una colección de scripts muy potente, que en un momento determinado, puede inclusive “impedirnos” la conexión remota al servidor si no tenemos muy claro lo que hacemos.
En este sentido, la ruta para la edición de su archivo de configuración, es:
/etc/csf/csf.conf
Dentro del mismo, tenemos 2 líneas que son muy interesantes:
TESTING = “1” – Si está activida esta regla así, es porque tu Firewall está en “modo de prueba” con lo cual, en función del valor asignado en el siguiente punto (testing_interval), pasado ese tiempo, te “borrará” todas las reglas de Firewall con el propósito de “regresar” a la normalidad. En otro caso, si has quedado conforme con la configuración de Firewall, puedes ponerle el valor de “0”, con lo cual, quedará aplicado este sistema.
TESTING_INTERVAL = “5” – Si las reglas de Firewall están en modo de prueba (testing), pasado número de minutos, se “limpiarán” del sistema, volviendo todo a la normalidad.
Bloquear accesos por país con firewall CSF y asignación de permisos de conexiones por país
Particularmente, CSF utiliza los 2 caracteres de país del código ISO de países CIDR (Classless Inter-Domain Routing – enrutamiento entre dominios sin clases) mediante el cual, se “clasifican” los rangos de direcciones IP de cada país. Como comenta CSF en el archivo de configuración, esta lista no es 100% segura ya que algunos ISPs, usan designaciones de IP para sus clientes mediante criterios no geográficos, lo cual dificulta su ubicación.
Por otra parte, la creación de reglas asociadas a grandes rangos de direcciones IP, pueden representar una disminución en el performance del servidor, con lo cual, no es muy recomendado para servidores VPS; aunque en mi caso, lo he usado en VPS de 1 GB de RAM y me fue muy bien, inclusive, me ayudó con tráfico indeseado.
Con ello en consideración, CSF se apoya en los 2 caracteres de país para la asignación en las reglas de Firewall, a partir de los bloques CIDR administrados por Maxmind GeoLite Country, el cual puedes consultar aquí: http://dev.maxmind.com/geoip/legacy/geolite/ (te sugerimos descargar el archivos CSV disponible para crear tus reglas con mayor seguridad y certeza).
Ahora bien, ¿qué haré? Permitiré el tráfico a México y Estados Unidos, y bloquearé al resto del mundo. Para ello, deberemos editar el archivo de configuración de CSF:
Ahora, guardamos el archivo, y reiniciamos el CSF:
sudo csf -r
Y revisamos las reglas aplicadas:
sudo iptables -L -n
Pasos finales
Por otra parte, con el objetivo de que nuestro Firewall tome acciones a partir de “falsos positivos” o “información confusa” proporcionada por los registros del sistema (syslog/rsyslog), en el archivo /etc/csf/csf.conf, debemos cambiar esto:
# 0 = Allow those options listed above to be used and configured
# 1 = Disable all the options listed above and prevent them from being used
# 2 = Disable only alerts about this feature and do nothing else
# 3 = Restrict syslog/rsyslog access to RESTRICT_SYSLOG_GROUP ** RECOMMENDED **
RESTRICT_SYSLOG = "0"
Por esto:
# 0 = Allow those options listed above to be used and configured
# 1 = Disable all the options listed above and prevent them from being used
# 2 = Disable only alerts about this feature and do nothing else
# 3 = Restrict syslog/rsyslog access to RESTRICT_SYSLOG_GROUP ** RECOMMENDED **
RESTRICT_SYSLOG = "3"
Con lo anterior, evitarás también “molestas” alertas del tipo:
*WARNING* RESTRICT_SYSLOG is disabled. See SECURITY WARNING in /etc/csf/csf.conf.
Goodie
CSF es un estupedísimo Firewal; para el caso de este material, podría decir que no está reservado solamente para “bloquear” rangos de IP´s de países sino para implementar un cortafuego por software a tu computadora o servidor.
Por ello, si modificas, en el siguiente conjunto de líneas, puede “decidir” qué puertos deseas mantener abiertos y en qué dirección:
…e inclusive, si permitirás que hagan “ping” a tu equipo:
# Allow incoming PING
ICMP_IN = "1"
Si has despertado la curiosidad con respecto a las capacidades de CSF, te recomendamos encarecidamente dar un vistazo a todo el fichero de configuración para hacer pruebas y descubrir sus posibilidades. ¡Te encantará! Cpanel lo integra generalmente a través de WHM, lo cual nos “garantiza” en cierto sentido su mejora y mantenimiento constante.
Nota final
Si al aplicar tus reglas de Firewall con CSF te aparece el mensaje de error:
*WARNING* URLGET set to use LWP but perl module is not installed, reverting to HTTP::Tiny
Es probable que te hayas olvidado de instalar paquetes de Perl de apoyo, con lo cual, solo hace falta instalar un módulo faltante mediante lo siguiente:
¿Qué pasa en este punto? Según comentan en algunos sitios, CSF implementó el procesamiento de peticiones para HTTP y HTTPS, con lo cual, el modelo LWP::UserAgent procesa muchísimo mejor HTTPS que el modelo HTTP::Tiny.
Si quisieramos evitar usar LWP, hay que buscar la línea:
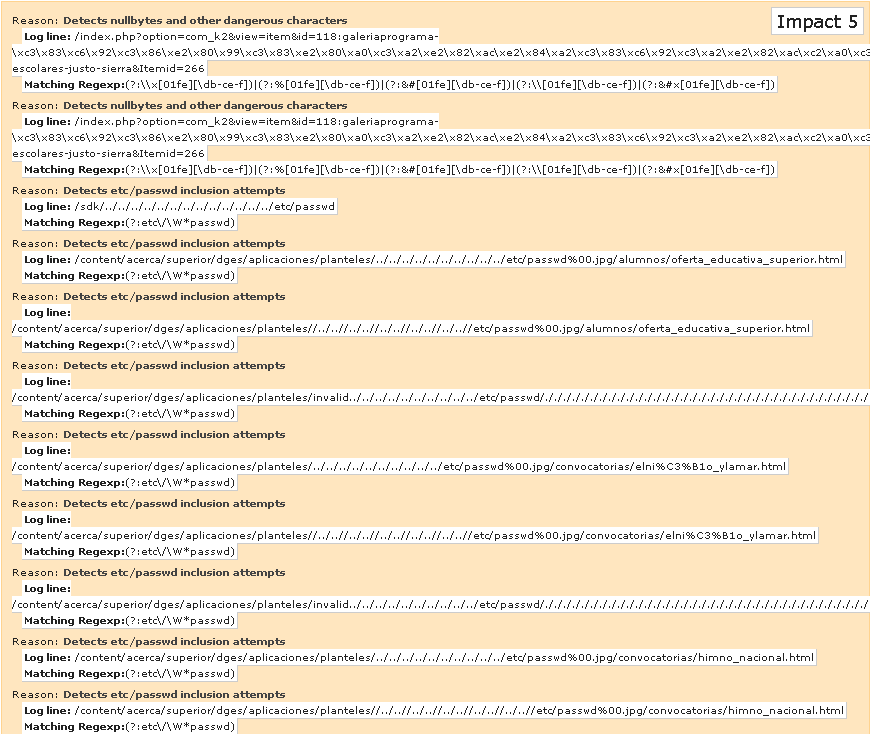
En temas de seguridad y protección de servidores, no existe nada mejor que proteger los mismos con aplicaciones de detección de intrusiones como Snort (https://www.snort.org/) o Suricata (http://suricata-ids.org/) u otras ofertas comerciales basadas tanto en hardware (firewalls) como Software (http://www.acunetix.com/) o servicios en la nube (https://www.cloudflare.com/) que actualizan con mayor regularidad sus bibliotecas y/o diccionarios de ataques, y están “más preparados” ante estas amenazas de la red Internet, por los que reaizar análisis de logs de Apache con Scalp! es una fantástica idea para prevenir y/o anticipar amenazas.
En esta ocasión les comparto un analizador de Logs muy sencillo, el cual propiamente, no es el más recomendado para “prevenir” ataques a un servidor Apache sino que más bien, su propósito es el de analizar potenciales huecos de seguridad o vulnerabilidades apoyándose de los registros (logs) que ha dejado atrás Apache para detectar aquellas áreas de oportunidad, mejora, e inclusive, vulnerabilidades propias de sistemas o aplicaciones desarrollados en PHP.
Scalp!, es un script analizador de logs del servidor Apache desarrollado en Phyton, que tiene como objetivo buscar problemas de seguridad. Su idea principal, es “leer” dentro de los registros de accesos al servidor para buscar patrones ataques potenciales mediante el envío de peticiones por los métodos HTTP/GET y HTTP/POST.
Para los propósitos de este post, he de comentar que estoy realizando pruebas sobre Ubuntu Server 14.04. En este caso, tengo una instalación con Apache 2, PHP5 y MySQL para un servidor Web, en donde mis “logs”, se encuentran dentro del directorio /var/logs/apache2/access.log.
Con esto en consideración, lo primero que tenemos que hacer, es “descargar” el script de Scalp! en nuestro directorio favorito:
(Nota: te sugiero que visites regularmente la página de Scalp! para descargar la última versión actualizada).
Ahora, descargamos el archivo de expresiones regulares que utiliza PHP-IDS (otra estupenda herramienta para proteger a nuestras aplicaciones PHP) para combinarlo en su uso con Scalp! mediante el siguiente comando:
En este caso, al ejecutar Scalp! por primera vez, me arrojó este mensaje de error:
The directory %s doesn't exist, scalp will try to create it
Loading XML file 'default_filter.xml'...
The rule '(?i:(\%SYSTEMROOT\%))' cannot be compiled properly
“Tuneando” nuestro fichero de patrones
Con respecto a la primera y segunda línea de error, no tenemos mayor problema. Más bien, el detalle que tenemos que resolver es que al parecer Phyton, no es capaz de “procesar” correctamente parte del contenido XML que descargamos de PHP-IDS. Para ello, la solución es muy sencilla, abrimos el archivo default_filter.xml con nuestro editor favorito:
A continuación, les aparecerá un mensaje como este, ante el cual, solo tenemos que esperar un poco (en función del tamaño de archivo de tu log o de las reglas que hayas pedido ejecutar):
Loading XML file 'default_filter.xml'...
Processing the file '/var/log/access.log'...
Scalp results:
Processed 491229 lines over 491413
Found 3175 attack patterns in 177.725208 s
Generating output in scalp-output/access.log_scalp_*
Ahora, solo tienes que ir al directorio scalp-output y “visualizar” en tu navegador en archivo generado para visualizar el reporte completo de patrones de ataque observados.
¡Esta herramienta es genial!
Goodie
Tecleando el comando:
python scalp-0.4.py --help
…podrás obtener la ayuda relacionada con otros patrones de uso de Scalp!.
Scalp the apache log! by Romain Gaucher - http://rgaucher.info
usage: ./scalp.py [--log|-l log_file] [--filters|-f filter_file] [--period time-frame] [OPTIONS] [--attack a1,a2,..,an]
[--sample|-s 4.2]
--log |-l: the apache log file './access_log' by default
--filters |-f: the filter file './default_filter.xml' by default
--exhaustive|-e: will report all type of attacks detected and not stop
at the first found
--tough |-u: try to decode the potential attack vectors (may increase
the examination time)
--period |-p: the period must be specified in the same format as in
the Apache logs using * as wild-card
ex: 04/Apr/2008:15:45;*/Mai/2008
if not specified at the end, the max or min are taken
--html |-h: generate an HTML output
--xml |-x: generate an XML output
--text |-t: generate a simple text output (default)
--except |-c: generate a file that contains the non examined logs due to the
main regular expression; ill-formed Apache log etc.
--attack |-a: specify the list of attacks to look for
list: xss, sqli, csrf, dos, dt, spam, id, ref, lfi
the list of attacks should not contains spaces and comma separated
ex: xss,sqli,lfi,ref
--output |-o: specifying the output directory; by default, scalp will try to write
in the same directory as the log file
--sample |-s: use a random sample of the lines, the number (float in [0,100]) is
the percentage, ex: --sample 0.1 for 1/1000
Si te interesa el tema, aquí puedes encontrar un estupendo artículo (en inglés) sobre una comparativa entre Snort y Suricata, los IDS (intrusion detection system) Open Source más populares. La liga es: http://wiki.aanval.com/wiki/Snort_vs_Suricata
En este tutorial, te enseñaré a realizar la configuración de un servidor proxy Squid + script de iptables.
Actualización 20210619.- Esta es una entrada de una publicación antigua en donde, para tener contexto de la época, casi todas las conexiones a sitios web se hacían mediante HTTP (80) y muy pocas sobre HTTPS (443). A pesar de ello, es muy probable que este script y archivo de configuración siga funcionando, así como también, te puede servir de base y referencia para jugar con tus propias configuraciones. KW.
Contexto
Resulta que cuando recién llegué a laborar en una organización, la misma tenía una red de aproximadamente 60 computadoras con una conexión a internet tipo ADLS de 2048 kbps (2 mbps) de bajada, y 256 de subida (0.25 mbps). Como ya imaginarán, la velocidad de conexión era lentísima, por lo cual me dí a la tarea de configurar un servidor Proxy Squid con reglas de Iptables para que pudieramos todos trabajar a gusto, bloquear algunas urls para los usuarios ociosos (juegos, pornografía, videos), etc. En fin, en ese entonces, trabajé sobre OpenSuSE 10.0 como sistema operativo y vale, ahora que tengo Internet en casa, me he configurado un servidor Proxy para mi red casera.
En fin, con todo lo anterior, pongo en sus manos una modesta configuración para Squid 2.6 STABLE5 sobre Debian 4 Etch junto con su respectivo Script de IPTables para que lo echen a andar en su casa o red. Debo mencionar que la configuración de estos servicios, podrían resultar ser no tan sencillos para el usuario novato, más sin embargo, les comentaré lo siguiente:
¿Qué es un servidor Proxy?
En el ámbito de las redes informáticas, el término proxy hace referencia a un programa o dispositivo que realiza una acción en representación de otro. La finalidad más habitual de un servidor proxy, es el de permitir el acceso a Internet a todos los equipos de una organización cuando sólo se puede disponer de un único equipo conectado, esto es, una única dirección IP.
Squid es un popular programa de software libre que implementa un servidor proxy y un demonio para caché de páginas web, publicado bajo licencia GPL. Tiene una amplia variedad de utilidades, desde acelerar un servidor web, guardando en caché peticiones repetidas a DNS y otras búsquedas para un grupo de gente que comparte recursos de la red, hasta caché de web, además de añadir seguridad filtrando el tráfico. Está especialmente diseñado para ejecutarse bajo entornos tipo Unix.
Netfilter es un framework disponible en el núcleo Linux que permite interceptar y manipular paquetes de red. Dicho framework permite realizar el manejo de paquetes en diferentes estados del procesamiento. Netfilter es también el nombre que recibe el proyecto que se encarga de ofrecer herramientas libres para cortafuegos basados en Linux.
El componente más popular construido sobre Netfilter es iptables, una herramientas de cortafuegos que permite no solamente filtrar paquetes, sino también realizar traducción de direcciones de red (NAT) para IPv4 o mantener registros de log. El proyecto ofrecía compatibilidad hacia atrás con ipchains hasta hace relativamente poco, aunque hoy día dicho soporte ya ha sido retirado al considerarse una herramienta obsoleta. El proyecto Netfilter no sólo ofrece componentes disponibles como módulos del núcleo sino que también ofrece herramientas de espacio de usuario y librerías.
Iptables es el nombre de la herramienta de espacio de usuario mediante la cual el administrador puede definir políticas de filtrado del tráfico que circula por la red. El nombre iptables se utiliza frecuentemente de forma errónea para referirse a toda la infraestructura ofrecida por el proyecto Netfilter. Sin embargo, el proyecto ofrece otros subsistemas independientes de iptables tales como el connection tracking system o sistema de seguimiento de conexiones, o que, que permite encolar paquetes para que sean tratados desde espacio de usuario. iptables es un software disponible en prácticamente todas las distribuciones de Linux actuales.
Ahora bien, se preguntarán seguramente, ¿para qué sirve Squid + Iptables en la red de una casa, empresa u organización? Mmmm, de mucho. Intentaré explicarlo de manera sencilla:
Imaginen que tienen 20 computadoras conectadas en su red mediante un switch directamente al modem ADSL de la compañía de su preferencia (Prodigy Infinitum de Telmex, por ejemplo), y resulta que esos 20 usuarios requieren entrar a una página como Hotmail, la cual tiene un peso específico (imágenes, documentos html, animaciones, etc.) de 300 kb cada vez que se conectan a ella. Como muchos seguramente sabrán, todos los navegadores destinan una carpeta en su disco duro para almacenar información en algo que llaman “caché”, el cual es un concepto que tiene como principal objetivo, “acelerar” la descarga en el futuro, y solo para esa PC cuando accedan más adelante a la misma página Web. Así pues, bajo nuestro escenario, si tenemos 20 usuarios que entren a Hotmail al mismo tiempo, estaríamos “descargando” entre todos, 6000 kb de información (20 usuarios X 300 kb = 6,000 kb) o lo que es lo mismo, 5.8 megas de información aproximadamente. ¿Qué sucedería en esta situación? Básicamente, que la conexión se alentaría para todos aún y cuando estén bajando todos lo mismo.
Y viene aquí la magia de Squid e Iptables (no puede vivir el uno sin el otro, eh), ya que, suponiendo que hemos destinado una vieja PC para hacerla de “proxy” y/o “router” mediante un servidor DHCP (ya platicaré de él en un post posterior), y conectándole un switch de 20 puertos para esas 20 pc´s, lo que sucedería es que la primer PC de nuestra red que intente establecer una conexión a Hotmail, le enviaría la petición a nuestro proxy para que haga una consulta, en la cual éste revisaría si está “almacenada” en la caché del servidor, y en caso de no ser así, se conectaría a Internet para “descargar” todos los elementos básicos del sitio (imágenes, scripts, animaciones, etc.), con el fin de devolver “la misma respuesta” a todas las demás computadoras. En otras palabras: si una computadora ha “accedido” con anterioridad a Hotmail, habrá “descargado” seguramente a nuestro proxy esos 300 kbs de los que hablaba, evitando “saturar” nuestra con “otras conexiones” similares, ahorrándonos así 5700 kb.
Instalación de un Servidor Proxy Squid
En mi caso, tengo una PC HP Pavilion a110m con un procesador AMD Atlhon a 1.67 mhz, 512 megas de memoria RAM, dos tarjetas de red PCI y disco duro de 40 gb. Mis tarjetas de red están configuradas de la siguiente manera:
ETH0 – Tiene una IP del tipo 192.168.1.XX, y está conectada directamente a mi a mi Modem ADLS Prodigy Infinitum
ETH1 – Tiene una IP fija del tipo 192.168.0.254, la cual conecta a mi switch (y la hace de servidor DHCP en la clase 192.168.0.x) y que funciona de “puerta de enlace” a los equipos que tengo conectados.
Para instalar Squid en Debian 4 Etch, solo tienen que hacer lo siguiente:
apt-get install squid
Y ¡listo!
Solo deberán acceder a la carpeta:
/etc/squid/
Renombrar el archivo squi/d.conf y “copiar” o dejar en su lugar el mío (o el que ustedes deseen configurar manualmente).
En el caso de mi Script de Iptables, yo lo he guardado en el directorio:
/etc/init.d/fw_squid
Y le he asignado permiso de ejecutable (chmod 777 /etc/init.d/fw_squid)
Ahora, hago que se cargue al inicio, agregándolo en el nivel 3 mediante el enlace simbólico:
ln -s /etc/init.d/fw_squid /etc/rc5.d/S20fw_squid
Y listo!
Caramba, en verdad podría elaborar todo un tutorial sobre esto, pero, vale, por cuestión de tiempo me resulta un poco difícil. Sin embargo, pongo a su disposición mis archivos de configuración a fin de que puedan hacer uso de ellos; en verdad, deseo que les sirvan:
/etc/init.d/squid restart – reiniciamos el servidor proxy squid
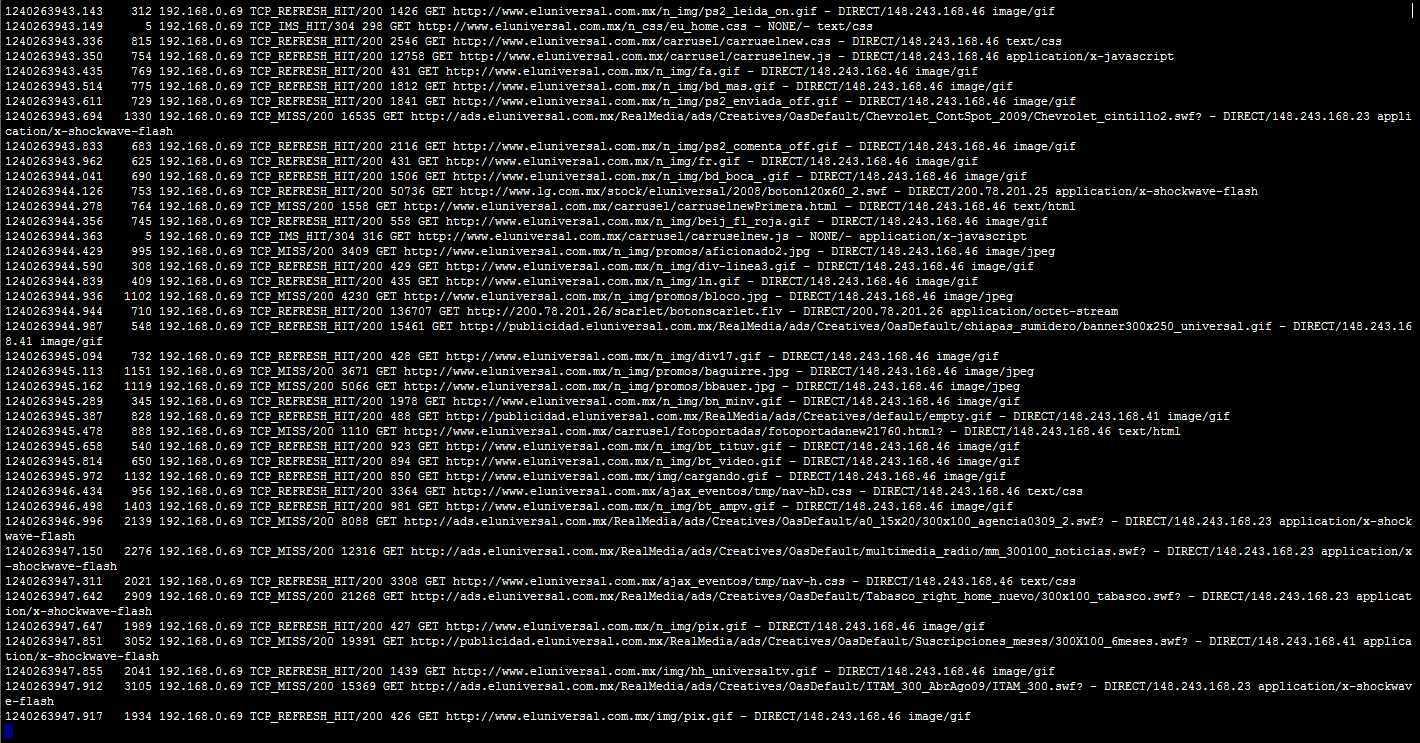
tail -fv /var/log/squid/access.log – “miran” en tiempo real las páginas que visitan las PC´s de su red
/etc/init.d/fw_squid.sh – ejecutan el script de iptables
iptables -L -n – sirve para ver qué puertos tienen cerrados, abiertos, bloqueados, etc.
¡Hasta pronto!
PD.- Se me olvidaba. Mi script de Iptables para proxy transparente con Squid, es también una joyita que los sacará de muchos apuros. En otra entrega les platicaré más sobre él. ¡Saludos!




Debe estar conectado para enviar un comentario.