Si eres administrador de plataformas de e-learning, director de una escuela, administrador de sistemas o profesor, seguramente te habrás preguntado en alguna ocasión cuántos usuarios soporta Moodle. No hay una respuesta simple o sencilla para ello ya que depende de varios factores por lo que en este artículo, te ayudaré a tener una mayor comprensión del tema para que evalúes y elijas correctamente lo que se ajuste a tu presupuesto.
Tabla de contenidos
Servidores y Servidores Web
Un servidor, tradicionalmente definido, es un equipo de cómputo conectado a una red de computadoras, con software configurado para tal propósito que tiene la capacidad de atender o dar respuesta a todas y cada una de las peticiones que recibe a través de la misma, según las especificaciones o protocolo utilizado y configurado para ello.

Por ejemplo, cuando Tim Berners Lee creó las especificaciones del protocolo HTTP para dar paso a la World Wide Web, configuró una computadora NeXT para desplegar y servir páginas web o “de hipertexto” a sus compañeros científicos en el CERN de Suiza, algo novedoso y completamente revolucionario.
En este sentido, el puerto asignado al protocolo HTTP fue el puerto 80. No obstante lo anterior, previo a esto, ya existía el puerto 20 para conexiones mediante consola a través de Telnet, puerto 21 para transferencia de archivos mediante FTP, puerto 22 para conexiones cifradas mediante consola mediante SSH, puerto 25 para correo electrónico y así sucesivamente. Para que un servidor o equipo de cómputo permitiese la conexión a estos puertos en una red, era necesario configurar en dicho equipo cada uno de ellos mediante programas que se ejecutan en memoria como “servicios”.
Así, en nuestra comprensión de qué es un “servidor”, podemos decir que cada puerto o protocolo tiene como misión y propósito proveer un “servicio” o conjunto de “servicios” a nuestros “clientes” según el protocolo que utilice. Así, un servidor web, puede ser entendido como un programa (el servidor web más popular es Apache seguido de Nginx mediante el puerto 80 (HTTP) o puerto 443 (HTTPS), el cual provee a nuestros usuarios del acceso a páginas web planas o de hipertexto (HTML) o bien, páginas generadas a través de procesadores de páginas de hipertexto como PHP, Phyton, etc.
Si un cliente (usuario, visitante, cibernauta, etc.) realiza una petición a nuestro servidor, de manera técnica lo que podemos decir es que solicita una respuesta a un servicio previamente configurado (servidor web Apache o servidor web Nginx) que está funcionando en ese momento en memoria para responder y dar respuesta a ello.
Con esto en consideración, y gracias a la generosidad de los entusiastas del software libre, hoy en día un servidor web puede cubrir múltiples funciones y satisfacer múltiples demandas.
¿Qué recursos necesito para implementar un servidor web?
Por ello, es importante mencionar que para que un sitio web complejo pueda funcionar basado en GNU/Linux, Apache, PHP y MySQL o MaríaDB (un servidor LAMP), a grandes rasgos, necesitarás de:
- Un servidor físico o virtual con conexión a Internet, espacio en disco duro suficiente, memoria RAM y otros recursos de misión crítica como procesador, sistema operativo, etc.
- Una dirección IP pública estática (o dinámica, más complejo de usar, pero no imposible de configurar) para tu servidor físico o virtual.
- Un software que actúe como servicio de servidor web como Apache o Nginx para el procesamiento e interpretación de páginas HTML mediante el protocolo HTTP.
- Un procesador o intérprete como PHP que facilite la generación dinámica de páginas de hipertexto.
- Un servicio que actúe como servidor de base de datos como MariaDB, PostgreSQL o MySQL.
Adicionalmente, si quieres tener URLs amigables para tu sitio web, requerirás de:
- Un nombre de dominio contratado del tipo misitioweb.com.
- Un servidor DNS que redireccione tu dominio contratado a la dirección IP pública estática (o dinámica) de tu servidor física o virtual.
Todo esto, en conjunto, requiere de una adecuada instalación instalación y configuración de paquetes y librerías que permitan optimizar y garantizar la disponibilidad de tus servicios, así como una correcta resolución de peticiones de los clientes, usuarios o visitantes de tu sitio web.

Con todo, ¿cuántos usuarios soporta Moodle?
En este punto, vamos a resolver tu duda y tratar de responder lo más objetivamente: antes de preguntarte cuántos usuarios soporta Moodle, debes tratar de encuadrar y definir primero tu problemática o escenario deseado en los siguientes términos:
- ¿Qué experiencia de usuario deseas brindar a tus alumnos y profesores?
- ¿Cuántos usuarios en total tienes programado atender?
- ¿Cuántos de estos usuarios serán concurrentes o se conectarán simultáneamente? ¿En qué momentos podrías tener alta demanda que derive en cuellos de botella?
- ¿Qué tanta tolerancia tendrías a respuestas lentas del servidor en horas pico?
- ¿Cuáles son tus perspectivas de crecimiento en el corto, mediano y largo plazo?
Con lo anterior en consideración, te daré un dato: Moodle es un LMS (Learning Management System) súmamente robusto que ofrece una gran cantidad de recursos para diseñar y programar nuestros cursos. Para que te des una idea, el código fuente o paquete comprimido de la versión de Moodle 4.2+, tiene un tamaño de archivo de 62.2 MB en formato tar.gz. Estos datos son determinantes para calcular cuántos usuarios soporta Moodle.
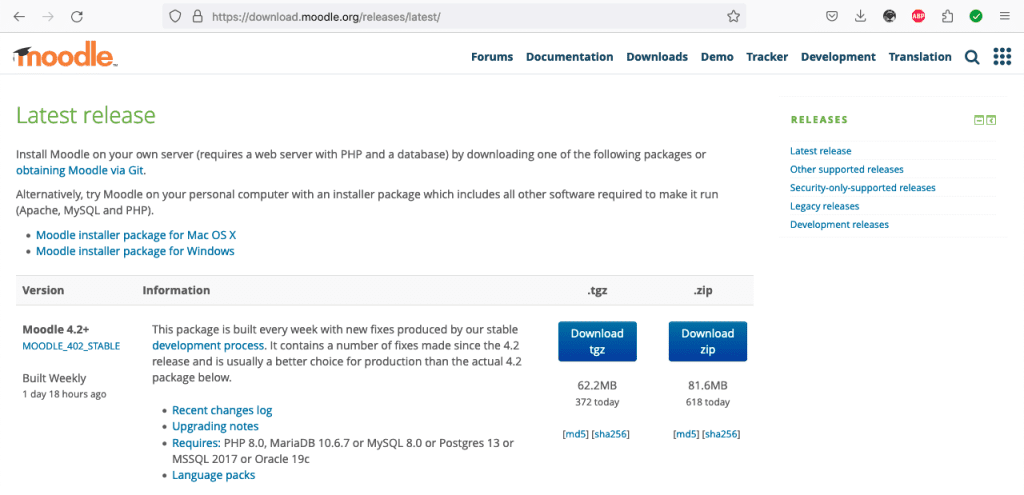
Ello no quiere decir que esos recursos ya descomprimidos estarán simultáneamente procesándose completa y enteramente en la memoria RAM del servidor; sin embargo, es un dato de referencia que no debemos perder de vista.
Con ello, más o menos desde la versión 1.x de Moodle, surgió una recomendación sobre la cantidad de memoria RAM que debe tener un servidor web para atender N número de usuarios: por cada 10 – 20 usuarios concurrentes, se recomienda tener disponibles 1 GB de memoria RAM.
A grandes rasgos, si tienes una escuela con 100 alumnos y esperas que los 100 se conecten al mismo tiempo (concurrencia), deberías de tener 5 GB de memoria RAM + unos 2 o 4 GB adicionales para al sistema operativo de tu servidor web Apache o Ngix.
Ahora bien, es probable que tus usuarios no estarán conectados las 24 hrs. del día de manera concurrente o simultánea sino que existan “eventos” más o menos “dispersos” a lo largo del tiempo por lo que, a manera de “riesgo calculado” podrías decidir decir: voy a destinar 2 GB de memoria RAM para Moodle + 2 GB para mi sistema operativo con los cuales atenderé a 100 usuarios en total, pero entiendo y comprendo que 40 usuarios concurrentes están garantizados.
Este es un escenario o panorama con riesgos calculados y tolerados.
¿Cuál es el escenario que te resulta ideal? ¿Qué tanta tolerancia tienes a probables demoras, fallos o errores?
En ambientes GNU/Linux, existen múltiples formas, si no tienes memoria RAM física pero sí un disco duro de estado sólido, para conseguir “memoria” adicional pero eso, será motivo de otro artículo.
Calcular el número de usuarios que soporta Moodle
Te dejo aquí un par de calculadoras en línea que he elaborado para que pueda obtener un estimado de:
- Cantidad de usuarios concurrentes en Moodle que soporta un servidor web en función de la cantidad de memoria RAM disponible.
- Cantidad de memoria RAM que necesitas para atender a N número de usuarios de Moodle de manera concurrente.
¡Utiliza las barras de desplazamiento!
Conclusiones
Como has podido observar, el performance o desempeño esperado de un servidor web y, sobre todo, de una instalación de Moodle, depende de una gran cantidad de factores como la cantidad de dinero que estás dispuesto a invertir en los recursos necesarios de servidor (memoria, disco, ancho de banda), riesgos tolerados, concurrencia de usuarios estimada, etc.
Ahora bien, cada instalación de Moodle es distinta así como el comportamiento de los usuarios.
Generalmente la concurrencia de usuarios suele darse en periodos de exámenes, por ejemplo, en las noches (un hábito que he observado sobre las nuevas generaciones o personas que trabajan en mi experiencia), etc.
Por lo anterior, en casi la totalidad de casos no es necesario destinar y garantizar el 100% de cumplimiento en recursos del servidor. Al final del día, la decisión es tuya; tú decides cuánto estás dispuesto a invertir y determinar qué calidad en la experiencia de usuario deseas brindar a tus usuarios.
Si deseas profundizar más sobre el tema, te recomiendo los siguientes artículos de Moodle:
- User site capacities: https://docs.moodle.org/19/en/User_site_capacities
- Performance FAQ: https://docs.moodle.org/402/en/Performance_FAQ










Debe estar conectado para enviar un comentario.