Hola, me especializo en la exploración de horizontes que ofrecen las nuevas tecnologías de la información para su incorporación en los procesos clave y de negocio de mis clientes de una manera orgánica, transparente y sin complicaciones.
Desde el año 1997, he sido usuario y entusiasta de los movimientos del software libre, open source y/o de código abierto en donde he vivido la experiencia de vida y trabajo en comunidad.
Actualmente, te ofrezco mis servicios de capacitación y consultoría en el campo de la capacitación y el E-learning para ayudar a las organizaciones a transitar sin sobresaltos a la transformación digital de las organizaciones, así como también, puedo ayudarte a construir tu tienda en línea para para vender por Internet tus productos y servicios e incursionar así a nuevos mercados mediante prácticas de comercio electrónico y marketing digital.
Si en algún momento deseas un tip o intercambiar notas, no dudes en contactarme, me encantará platicar contigo sobre GNU/Linux, E-learning, Design Thinking, Comercio Electrónico, Marketing Digital, Capacitación, Open Source, Debian, Ubuntu, Filosofía y muchas cosas más.
Tráiler oficial de Matrix Resurrections en español américa latina
The Matrix Resurrections Soundtrack | Opening – Johnny Klimek & Tom Tykwer
Opening – Johnny Klimek & Tom Tykwer | From The Matrix Resurrections Soundtrack Available now: https://lnk.to/MatrixResurrectionsID Listen to more from The Matrix Resurrections: https://www.youtube.com/playlist?list… Subscribe to WaterTower Music on YouTube: http://bit.ly/WaterTowerSub#TheMatrix#Soundtrack Tracklisting: 1. Opening – The Matrix Resurrections 2. Two and the Same 3. Meeting Trinity 4. It’s in My Mind 5. I Fly or I Fall 6. Set and Setting 7. Into the Train 8. Exit the Pod 9. The Dojo 10. Enter IO 11. Inside IO 12. Escape 13. Broadcast Depth 14. Exiles 15. Factory Fight 16. Bullet Time 17. Recruiting 18. Infiltration 19. I Like Tests 20. I Can’t Be Her 21. Simulatte Brawl 22. Swarm 23. Sky Scrape 24. My Dream Ended Here 25. Neo and Trinity Theme (Johnny Klimek & Tom Tykwer Exomorph Remix) 26. Opening – The Matrix Resurrections (Alessandro Adriani Remix) 27. My Dream Ended Here (Marcel Dettmann Remix) 28. Nosce (Almost Falling Remix) 29. Bullet Time (Moderna Remix) 30. Back to the Matrix (Eclectic Youth Remix) 31. Welcome to the Crib (System 01 Remix) 32. Flowing (Thomas Fehlmann Remix) 33. Temet (Esther Silex & Kotelett Remix) 34. Choice (Psychic Health Remix) 35. Monumental (Gudrun Gut Remix) Connect with WaterTower Music: Follow WaterTower Music on Instagram: https://www.instagram.com/watertowerm… Follow WaterTower Music on TIKTOK: https://www.tiktok.com/@watertowermusic Like WaterTower Music on Facebook: https://www.facebook.com/WaterTowerMusic Follow WaterTower Music on Twitter: https://twitter.com/watertowermusic Visit WaterTower Music at: https://www.watertower-music.com/ Connect with The Matrix: Follow The Matrix on INSTAGRAM: https://www.instagram.com/TheMatrixMo… Like The Matrix on FACEBOOK: https://www.facebook.com/TheMatrixMovie/ Follow The Matrix on TWITTER: https://twitter.com/TheMatrixMovie About WaterTower Music: WaterTower Music, the in-house label for the WarnerMedia companies, releases recorded music as rich and diverse as the companies themselves. It has been the soundtrack home to many of the world’s most iconic films, television shows and games since 2001. Featured releases include the soundtracks for Aquaman, The Hobbit, Game of Thrones, Crazy Rich Asians, King Arthur, Justice League, Westworld, and Dune The Matrix Resurrections Soundtrack | Opening – Johnny Klimek & Tom Tykwer https://youtu.be/scU4PvPmqAM
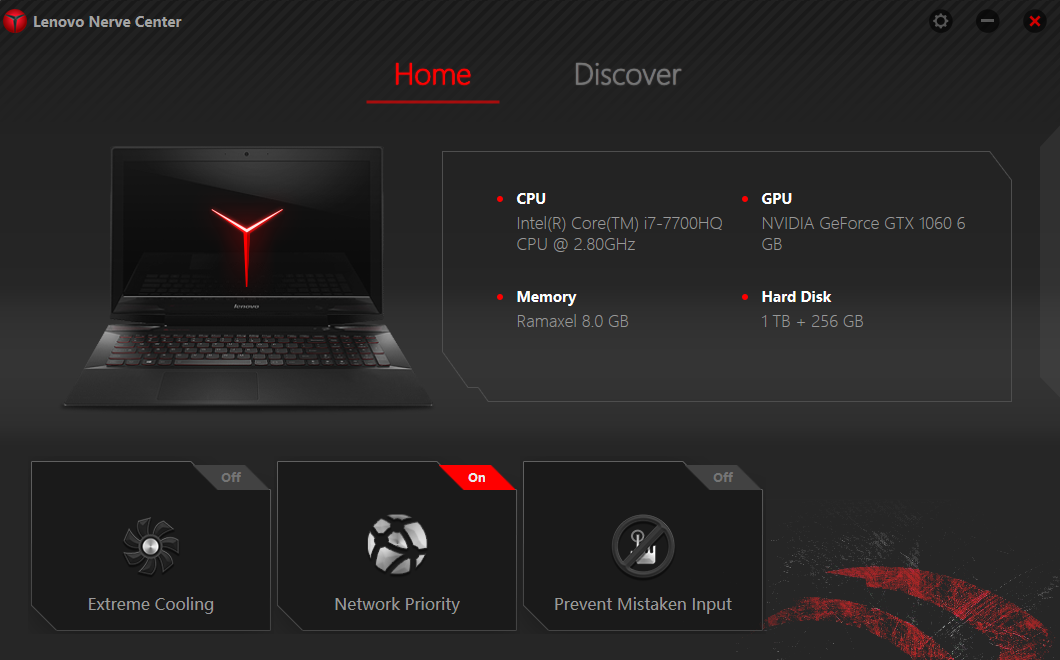
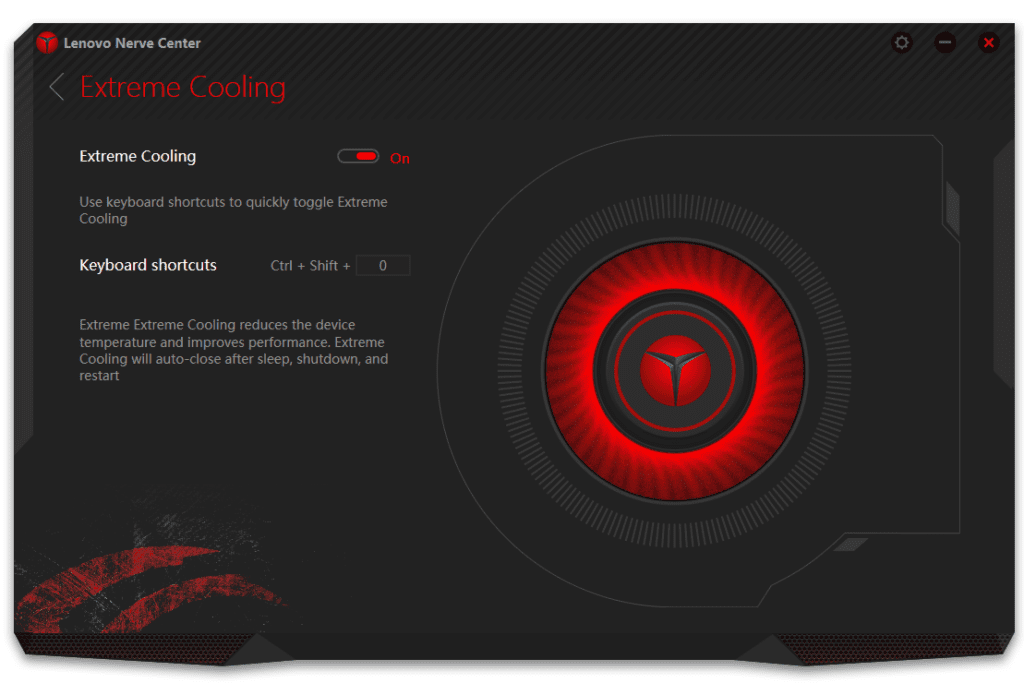
Tuve la necesidad de reinstalar Windows desde cero en mi computadora Lenovo Y720 con lo cual, al instalar los drivers, me pareció extraño no encontrar una herramienta que me resultaba de gran utilidad para “echar a andar” los ventiladores que me permiten refrigerar y mejorar el rendimiento de CPU / tarjeta gráfica a voluntad, y por la cual me era imposible Instalar el software Lenovo Nerve Center que acompañó a mi laptop desde que la compré por ahí del año 2017.
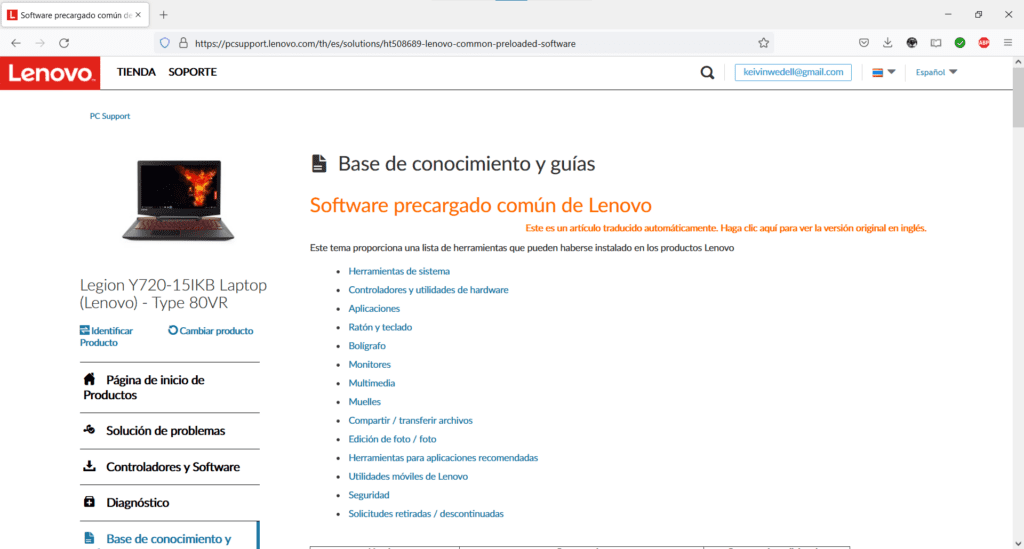
Pues bien, el tema es el siguiente: en la base de conocimiento de Lenovo que puedes consultar en https://pcsupport.lenovo.com/th/es/solutions/ht508689-lenovo-common-preloaded-software, comentan que el Lenovo Nerve Center que viene dentro de la lista de software precargado de los equipos Legion Y720-15IKB, ha sido descontinuado o al alcanzado el fin del periodo de vida.
Con ello en consideración, establecí una sesión de chat con un técnico de Lenovo a quien le expuse la situación y el problema para conseguir el Lenovo Nerve Center, el cual dejó de estar disponible tanto para descarga en la página web de Lenovo como en Tienda de Microsoft para su instalación, y lo único que me comentó fue:
Que software Lenovo Nerve Center ya no estaba disponible.
Que el Lenovo Nerve Center presentó una vulnerabilidad (no me dijeron cual, ni en qué consistía).
Que me recomendaba utilizar un software de terceros (bajo mi propia responsabilidad y riesgo).
Que no saben cómo activar los ventiladores si saldrá una actualización, driver o mejora.
Mi comentario al técnico fue simple: era frustrante y decepcionante que Lenovo decidiera eliminar una característica fundamental (y razón por la cual mucha gente compramos este tipo de equipos, ¡ventilación, refrigeración, rendimiento!) sin ofrecer una alternativa, software sustituto o drivers mejorados u optimizados. Sinceramente, Lenovo nos ha dejado solos. Esto haciendo y documentando lo que Lenovo tendría que informar a sus clientes.
No obstante lo anterior, te comparto un tip y mi experiencia para recuperar y/o volver a instalar el software Lenovo Nerve Center (un poco “forzado” el tema y esperando que Microsoft no retire la app de la Tienda pronto).
¿Cómo instalar el software Lenovo Nerve Center de nuevo en tu laptop?
Los pasos que tienes que seguir son los siguientes:
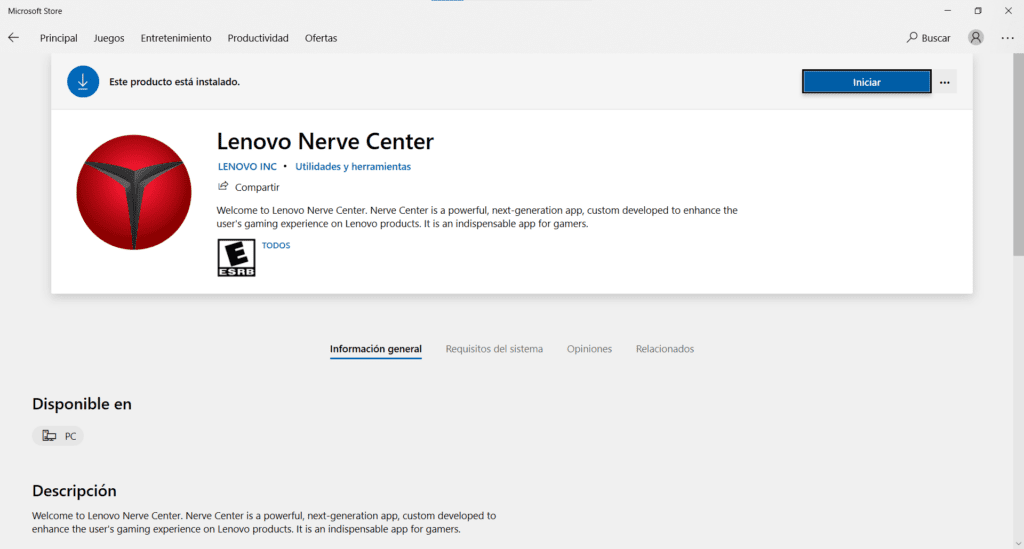
Abre el software Lenovo Nerve Center; realizará una comprobación rápida y te pedirá que actualices tu software desde la Tienda de Microsoft.
Instala el Lenovo Nerve Center desde la Tienda de Microsoft.
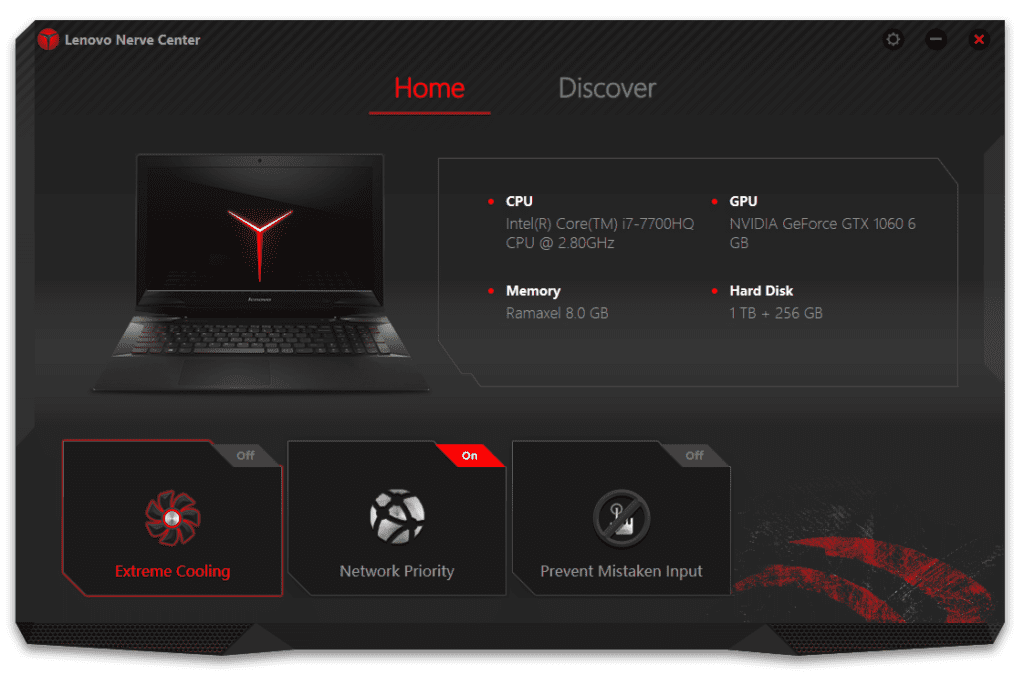
¡Y listo! Ya tienes nuevamente el Lenovo Nerve Center en tu equipo.
Espero que este truco te haya servido; para mí, en el día a día, esta herramienta me es fundamental en mis tareas de trabajo de edición de gráficos y video. Es ruidoso el ventilador, lo sé, pero funciona.
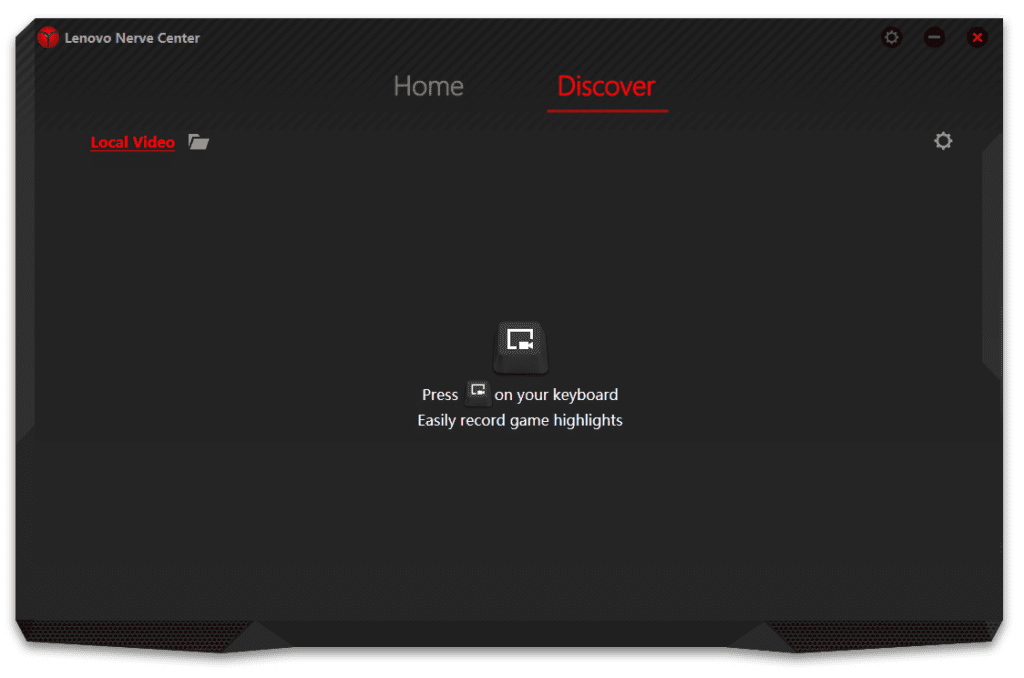
Tip adicional sobre este tema
Sin el software Lenovo Nerve Center, un par de botones del teclado más, quedarían inutilizados:
El botón de grabación / captura de video de la pantalla de tu computadora (muy útil para aquellos Gamers a quienes les gusta grabar sus partidas de videojuegos).
La función de la tecla de inicio del software Lenovo Nerve Center.
Algo pasó por ahí; desconozco las razones por las cuales Lenovo decidió descartar esta herramienta, pero aquí la tienes de nuevo. En verdad, espero que te sirva.
Con el surgimiento de la red Internet y desarrollo de la sociedad de la información y el conocimiento, de poco en poco, se han instalado en nuestra vida cotidiana herramientas tecnológicas para el día a día de nuestra vida digital como el uso del correo electrónico y, con ello, la necesidad de disponer de servicios de almacenamiento gratuito en la nube.
En sus primeros días, Google comenzó ofertando una cuenta de Gmail que, progresivamente y conforme pasaba el tiempo, te incrementaba el espacio de almacenamiento hasta que eso terminó. Así, Google entendió de manera temprana que la venta de espacio de almacenamiento era una buena idea de negocio (y una eventual necesidad de todo cibernauta) con lo cual, de poco en poco, hemos visto desfilar una multitud de alternativas que hacen más fácil nuestras vidas.
Como toda tecnología o actividad, es de reconocerse también el lado oscuro que se le ha dado también a este tipo de servicios como lo es el almacenamiento y compartición de material protegido por derechos de autor como software, música, películas, libros, etc., hasta otro tipo de materiales como pornografía e, inclusive, terrorismo.
No obstante lo anterior, los servicios de almacenamiento gratuito en la nube son un estupendo recurso para nuestra vida digital, tanto para su uso a través de nuestro celular mediante las apps que ofrecen como en su día a día a través del navegador web, por lo que te dejamos una breve reseña de aquellos más fáciles de usar y con las mejores prestaciones.
Mega
Liberado el el 19 de enero de 2013 y desarrollado por Kim Dot Com, un controversial hacker que ideó e implementó la autentificación de 2 factores y el cifrado de información a partir de la experiencia acumulada con el servicio de almacenamiento en la nube que le precedió, y del cual también fue creador (Megaupload creada en 2005), a partir de demandas y denuncias de infracción de copyright, derechos de autor, software y programas, Mega es la evolución de un servicio que te ofrece privacidad, cierto grado de anonimato y sobre todo, el cifrado de tu información para asegurar que, en caso de que sus servidores sean intervenidos (Megaupload fue intervenido y suspendido por el FBI en 2012) , sea imposible poder descifrar la información.
En la versión gratuita, tienes acceso a 20 GB de almacenamiento.
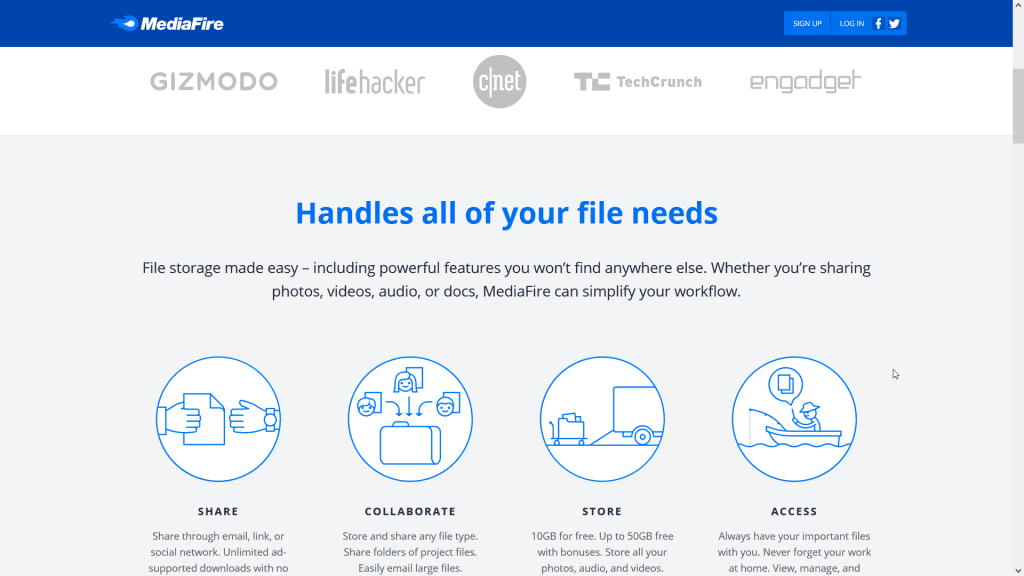
Lanzado al público de manera local en 2006, y resto del mundo en 2007, es un popular servicio que ha logrado matenerse en las preferencias de los usuarios debido a sus escasas limitaciones y gratuidad; involucrado también en el mundo de las controversias de almacenamiento de contenido protegido por derechos de autor, Mediafire nos ofrece hoy en día 10 GB de almacenamiento gratuito en la nube; eso sí, si quieres almacenar archivos de gran tamaño, tendrás que pagar.
Desde su fundación, Google se ha caracterizado por poner brindar a los usuarios, estupendas herramientas y servicios integrados a través de una única cuenta para mejorar nuestra presencia y productividad en la red. Con la aparición de Gmail por ahí del año 2003, Google Drive vio la luz el 24 de abril de 2012 para potenciar su motor de correo electrónico y permitirnos así, compartir, archivos electrónicos de mayor tamaño.
Al día de hoy, cada cuenta gratuita de Google te brinda hasta 15 GB de espacio de almacenamiento pero, si requieres de mayores prestaciones, existe la versión Google One (para aumentar tu almacenamiento) que va de precios de $34.00 MXN al mes por 100 GB o $169.00 MXN al mes por 2 TB, o Google Workspace que te ofrece otros esquemas de almacenamiento potenciado por servicios adicionales como Meet con mayores prestaciones.
Un punto a destacar de Google Drive, es la capacidad que tiene para permitirte crear y editar documentos electrónicos (procesador de textos, hoja de cálculo, presentaciones y formularios, entre otras herramientas) de una manera completamente on line, a través de tu navegador, y sin pago adicional de licencias.
Este servicio, es la apuesta presentada por Microsoft el 18 de febrero de 2014 para hacer frente a la competencia presentada por Google y otras plataformas que constituye una buena alternativa para integrarse de manera transparente con Microsoft Windows. Inicialmente, ofrecía mayor capacidad de almacenamiento que fue disminuida a los 5 GB actuales que te ofrece.
Al igual que Google Drive, también te permite acceder de manera gratuita a una versión web u on line de sus icónicas aplicaciones de elaboración de documentos electrónicos en la nube mediante Word (procesador de textos), Excel (hoja de cálculo), PowerPoint (presentaciones), OneNote (notas) y formularios entre otras utilidades.
Si necesitas un software de ofimática y no puedes permitirte pagar una licencia de software o no deseas usar LibreOffice, OneDrive es una excelente alternativa para continuar trabajando con Microsoft Office de manera gratuita gracias a la nube.
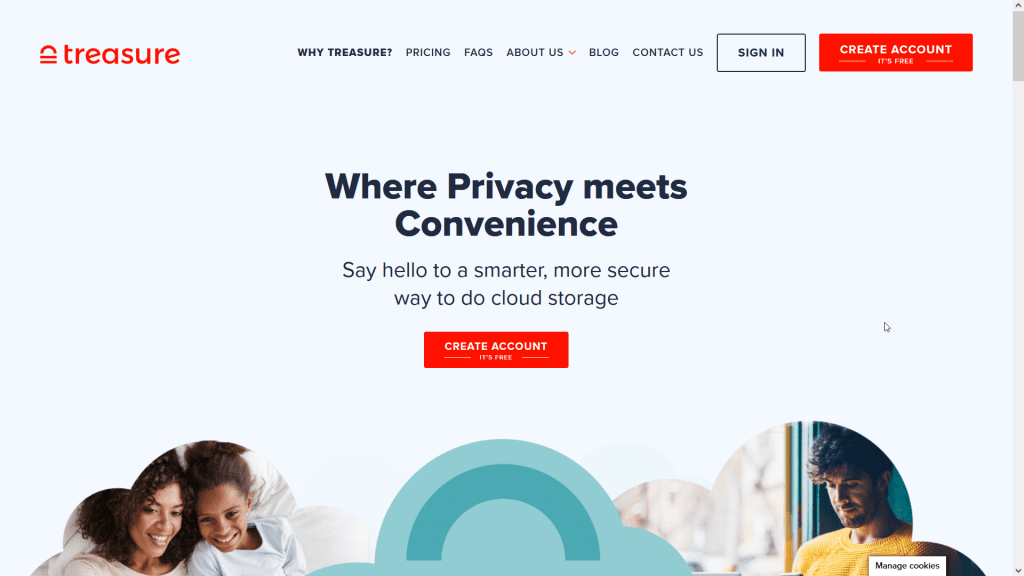
Treasure.cloud es un particular servicio que me ha llamado mucho la atención: aboga por la privacidad y el cifrado de tus datos. Además, tiene un programa a través del cual, si afilias a un amigo a través de una invitación realizada a través de tu cuenta, puedes “ganar” 10 GB por cada activación que consigas a través de tus recomendaciones. Para cuentas nuevas, puedes disponer de 10 GB de espacio, teniendo como un punto a favor que no tiene muchas limitaciones.
Box.com, es otro servicio de almacenamiento gratuito en la nube muy fácil de usar, simple, y el cual cubre sin mayor contratiempo ni dificultad lo que ofrece. La versión gratuita te permite disponer de hasta 10 GB de almacenamiento con el único inconveniente de que tus archivos individuales, no tengan un peso mayor de 250 MB. A pesar de todo, es una gran herramienta para guardar nuestras fotografías, documentos de trabajo, etc.
¿Necesitas compartir algo pero que el link tenga fecha de caducidad? Este servicio es para tí: con 2 GB de espacio gratuito, tendrás la opción de que los links compartidos tengan una vigencia de 15 días, momento en el cual tus documentos compartidos perderán vigencia.
Si tienes instalada alguna distribución GNU/Linux conviviendo con Windows, es muy probable que te resulte molesto (y necesario) sincronizar la hora entre Windows y Linux.
Este “detalle” (porque no es un problema realmente), se debe a que estos ambos sistemas operativos, gestionan de manera distinta el tiempo: en el caso de una gran mayoría de distribuciones GNU/Linux, se utiliza los esquemas UTC (Universal Time Coordinated) o GMT (Greenwich Mean Time) que no son otra cosa que formas universales de “comprender” el tiempo y zonas horarias; en otro sentido, los sistemas operativos Windows, utilizan los esquemas de “Hora Local” (Localtime) que al día de hoy, se encuentran asistidos por NTP (Network Time Protocol) para “sincronizar” relojes entre dispositivos.
La hora local, no es más que la “hora” de una zona horaria particular que “establece” el usuario o bien, que establece tu servidor NTP en función de la región que le hayas indicado.
Así, Network Time Protocol (NTP) es un protocolo de Internet para sincronizar los relojes de los sistemas informáticos a través del enrutamiento de paquetes en redes con latencia variable, y el UTC se obtiene a partir del Tiempo Atómico Internacional, un estándar de tiempo calculado a partir de una media ponderada de las señales de los relojes atómicos, localizados en cerca de 70 laboratorios nacionales de todo el mundo.
Debido a que la rotación de la Tierra es estable, pero no constante y se retrasa con respecto al tiempo atómico, UTC se sincroniza con el tiempo medio de Greenwich (obtenido a partir de la duración del día solar), al que se le añade o quita un segundo intercalar cuando resulta necesario, siempre a finales de junio o diciembre. La decisión sobre los segundos intercalares la determina el Servicio Internacional de Rotación de la Tierra y Sistemas de Referencia, basándose en sus mediciones de la rotación de la Tierra..
Para serte honesto, el modelo UTC es un esquema de gestión del tiempo universal más apropiado que garantiza interoperabilidad.
Lo anterior, es la razón por la cual, si tienes una instalación Windows con GNU/Linux conviviendo, es muy seguro que tengas Dual Boot instalado (también conocido como Arranque Dual) por lo que habrás notado que en tu distribución GNU/Linux obtienes la hora exacta sin mayor inconveniente pero, al arrancar sesión en Windows, obtienes una hora distinta que no concuerda con tu zona horaria.
Para resolver esto, tienes 2 opciones:
Opción A: Obligar a Windows a utilizar el esquema de Coordinación de Hora Universal (UTC)
En mi caso, esta sería mi opción favorita porque representa la oportunidad de hacer que tu sistema operativo respete y se ajuste a los estándares de sentido de comunidad y convivencia. Además, será capaz de actualizarse sin problemas durante los cambios de horario de invierno y verano, o simplemente, durante al paso a una zona horaria distinta.
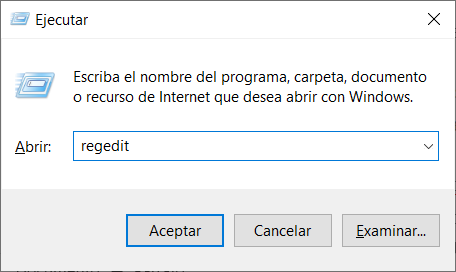
Para configurar este esquema, presiona la combinación de tecla Windows + R y escribe “regedit” para abrir el editor de registro de Windows:
Iniciamos el editor de registro de Windows.
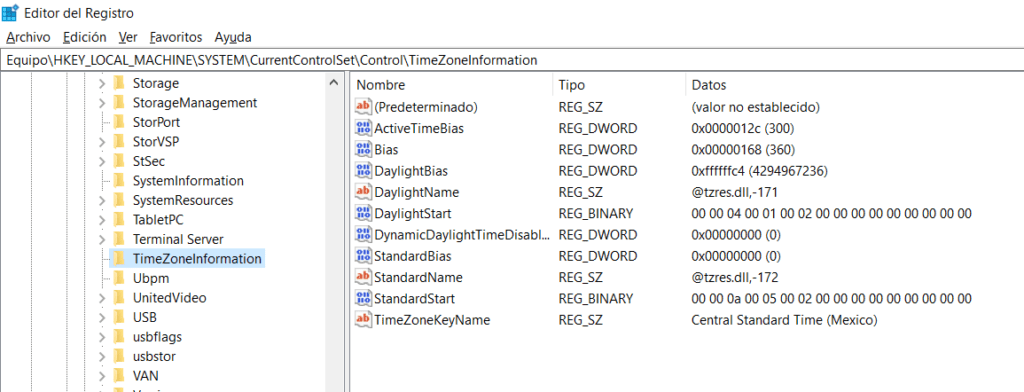
Ahora, busca dentro de los registros, la siguiente clave:
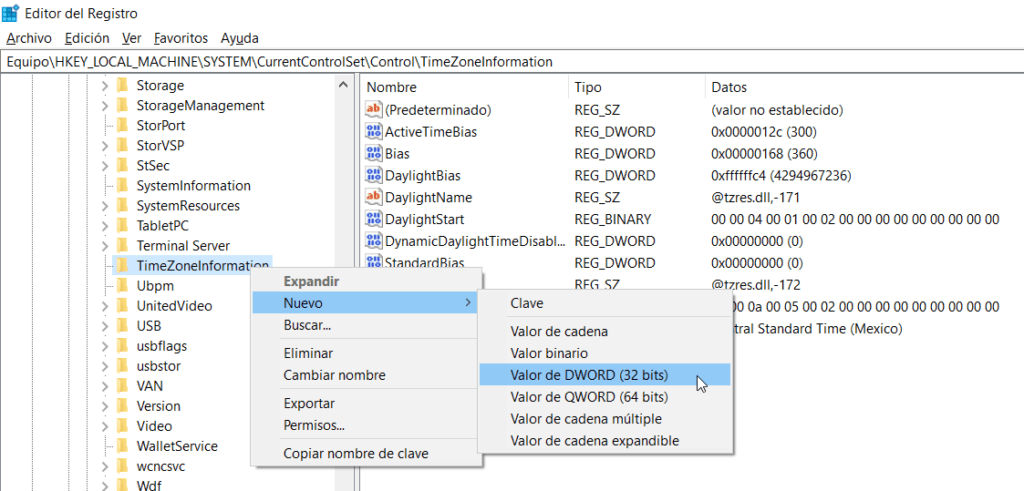
A continuación, haz clic con el botón derecho del mouse sobre la carpeta TimeZoneInformation y crea un valor dword al cual deberás poner por nombre “RealTimeIsUniversal”:
Añadimos un valor DWORD…
RealTimeIsUniversal
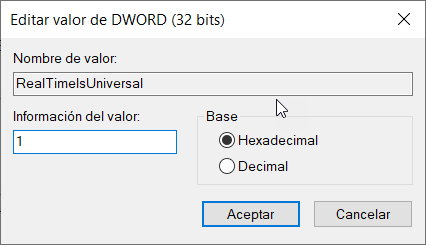
Ahora, haz doble clic sobre el valor “RealTimeIsUniversal” creado y asígnale el valor de “1”:
Una vez hecho lo anterior, deberemos ahora desactivar la sincronización automática de hora en Windows; para ello, escribe en la barra de búsqueda de Windows el comando CMD y selecciona la opción “Ejecutar como administrador”:
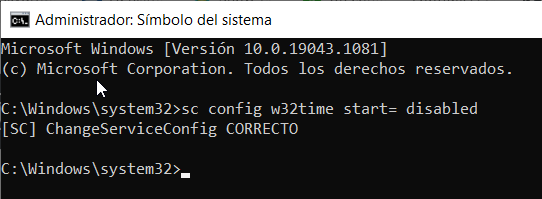
sc config w32time start= disabled
Si todo ha funcionado bien, observarás un mensaje como este, ¡y es todo!
Nota: Si en algún momento deseas revertir los cambios, solo debes el valor de la entrada “RealTimeIsUniversal” a “0” para volver a trabajar con la hora local.
Opción B: Obligar a GNU/Linux a utilizar el esquema de Hora Local (localtime)
En GNU/Linux el tema es más simple, ya que solo tienes que ejecutar el siguiente comando como administrador:
Si eres instalaste alguna distribución de GNU/Linux en tu computadora y la configuraste para convivir junto con Windows, seguramente te podrá resultar “molesto” que tu distribución sea la primera en iniciar cada que enciendes tu computadora; por ello, para que tu computadora pueda recordar el último sistema operativo en Linux, solo debes seguir los siguientes pasos:
1.- Abre una sesión de terminal y edita el archivo /etc/default/grub
sudo nano /etc/default/grub
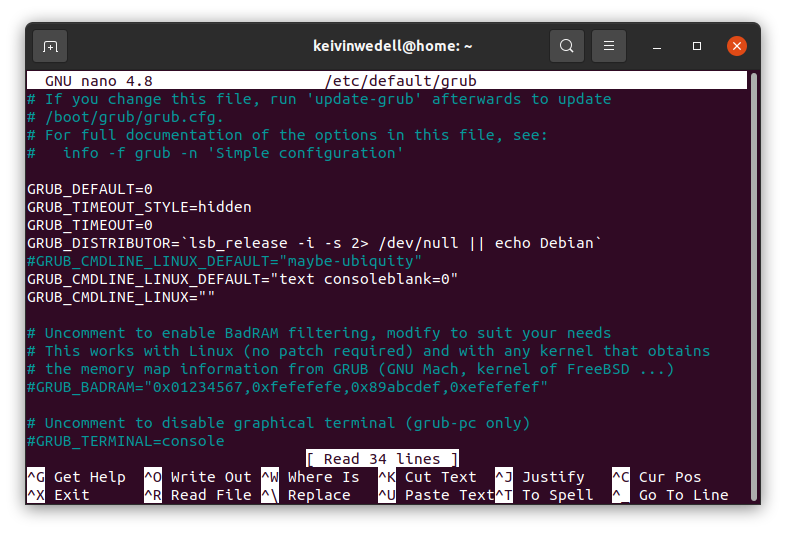
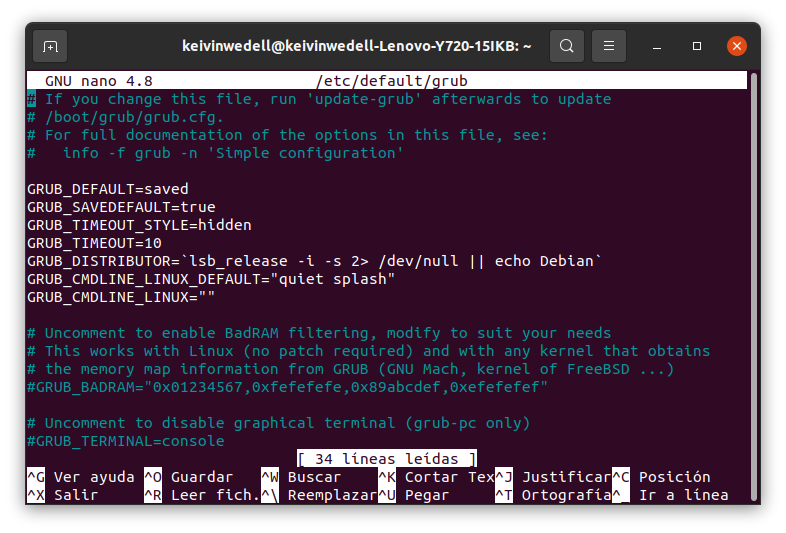
2.- Una vez abierto, verás algo como esto:
Aquí, deberás cambiar la línea..
GRUB_DEFAULT=0
…por la línea:
GRUB_DEFAULT=saved
…y deberás añadir también la línea:
GRUB_SAVEDEFAULT=true
…y guardar los cambios de tu archivo.
Te recomiendo mucho verificar que escribas correctamente las líneas para evitar problemas en la reconfiguración del arranque de inicio; revisa bien antes de guardar cambios.
Si todo está correcto, tu archivo del cargador de arranque GRUB deberá verse algo así:
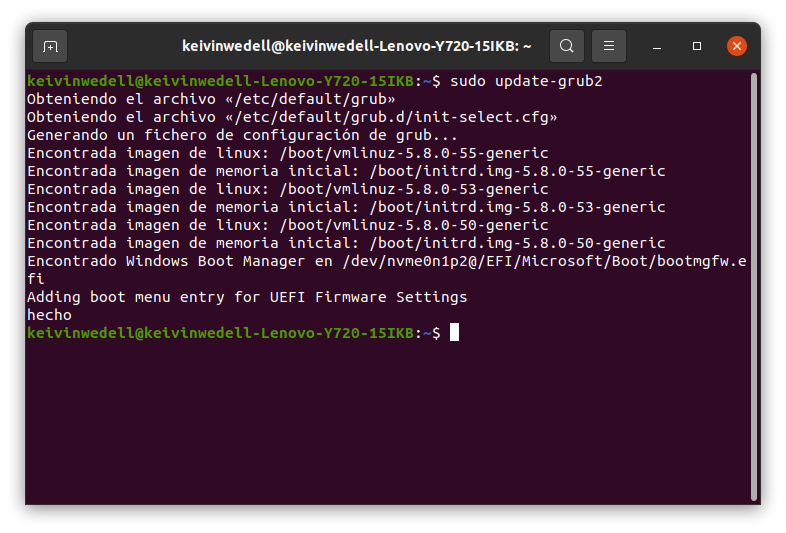
3.- Ahora, solo resta indicarle a Linux que aplique los cambios en el cargador de arranque ejecutando el siguiente comando:
sudo update-grub2
¡Y listo! Tu cargador de arranque estará listo y programado para iniciar y recordar el último sistema operativo con el que iniciaste la computadora.
En casi cualquier institución educativa, organización, empresa, negocio u hogar, es muy común que tengamos alguna computadora o equipo que ya no utilicemos, se encuentre un poco obsoleto, o simplemente esté en desuso. Por ello, te voy a enseñar a configurar un servidor de archivos Samba en Ubuntu con el propósito de que puedas recuperar y darle nueva vida a ese dispositivo.
Veamos: en el ámbito de las redes de área local en donde conviven computadoras con Windows instalado, siempre ha resultado de gran utilidad la posibilidad que crear carpetas compartidas mediante las cuales, podamos transferir fácilmente documentos, guardar música, crear respaldos de información, etc.
En este sentido, si bien es cierto que tanto Mac como Windows disponen esta función de manera nativa o bien, existen alternativas en la nube como NextCloud (un día de estos haremos un tutorial sobre ello), también es cierto que puedes configurar un servidor de archivos Samba independiente asociado a cuentas de usuario para agregar una capa de seguridad independiente a la de tu sistema operativo, accesible desde Internet, y que cumple estándares para “crear” unidades compartidas de red.
Instalación de Samba
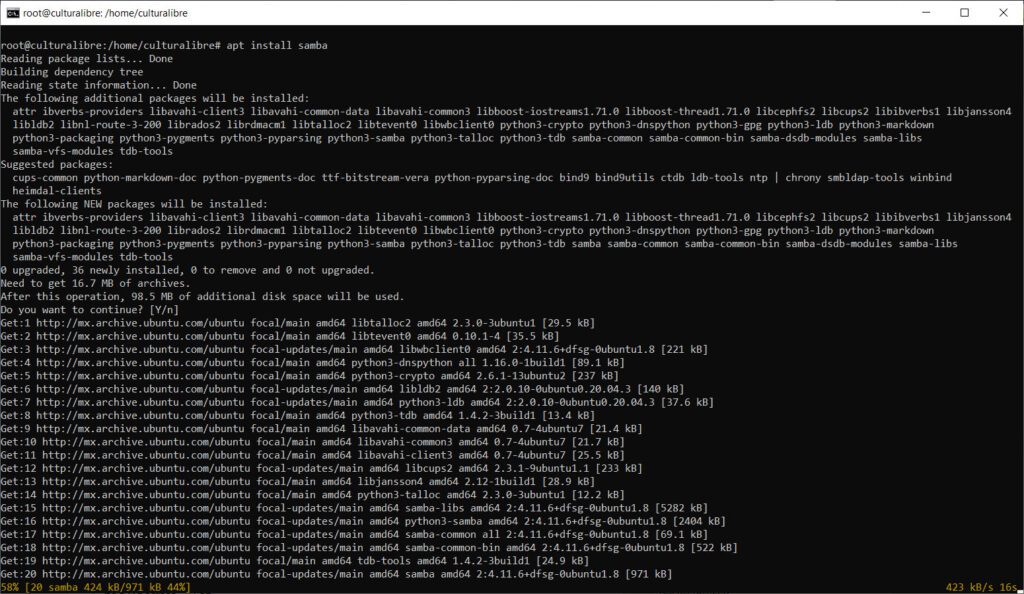
Para lograr lo anterior, y partiendo del punto de que dispones de una instalación de GNU/Linux Debian, Ubuntu, LinuxMint o derivadas, lo primero que tienes que hacer es realizar la instalación de los paquetes de Samba. Para ello tecleamos:
sudo apt install samba
Configuración de Samba
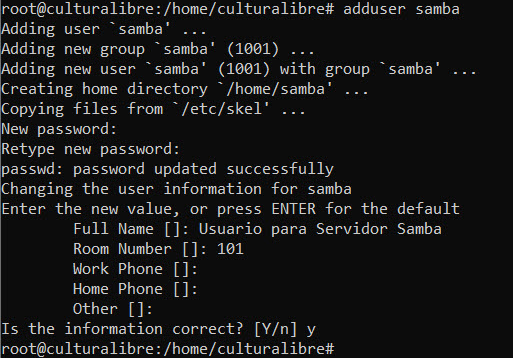
Ahora, crearemos una cuenta de usuario en nuestro sistema operativo (para nuestro caso, crearé el usuario “samba”) mediante el siguiente comando:
sudo adduser samba
Solo deberás asignarle una contraseña y completar algunos datos (si así lo deseas) para identificar y completar información de tu usuario:
Tip: si en algún momento en el futuro deseas cambiar la contraseña a tu usuario, solo deberás teclear algo como esto:
sudo passwd samba
Ahora, si todo ha salido bien, es momento de modificar el archivo de configuración de Samba que se ubica en /etc/samba/smb.conf; para ello, utilizaremos el editor de texto nano, con lo cual es pertinente teclear:
sudo nano /etc/samba/smb.conf
A continuación, verás una pantalla como esta:
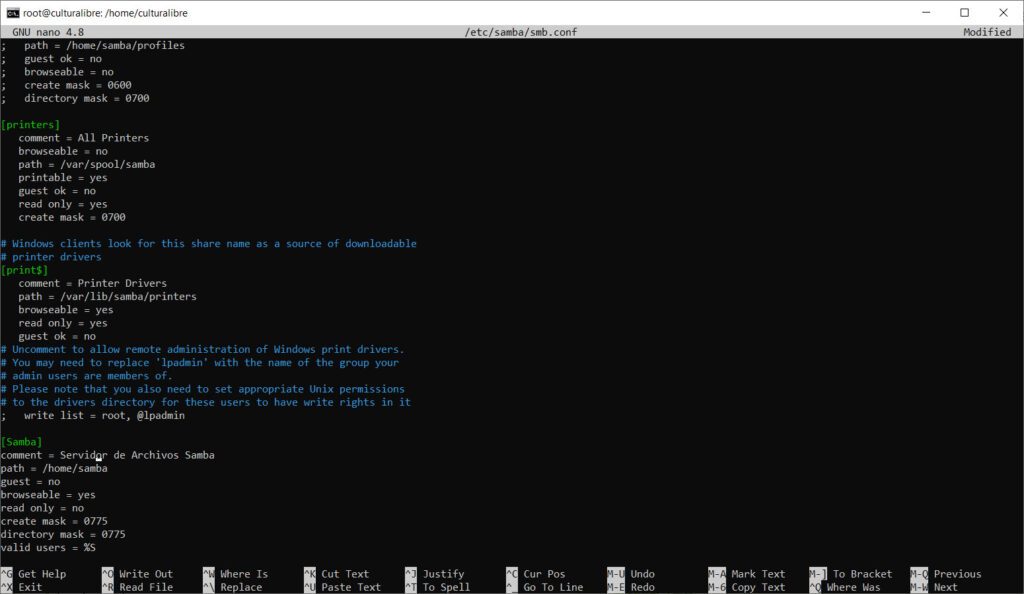
Solo debes ir al final del archivo y añadir la siguiente configuración:
[Samba]
comment = Servidor de Archivos Samba
path = /home/samba
guest = no
browseable = yes
read only = no
create mask = 0775
directory mask = 0775
valid users = %S
Guarda los cambios en nano (presionando CTRL + O y Y) y regresemos a la consola (presionar letra Q). Con ello, deberemos ahora agregar el usuario Samba al servidor de archivos Samba (valga la redundancia) mediante el siguiente comando:
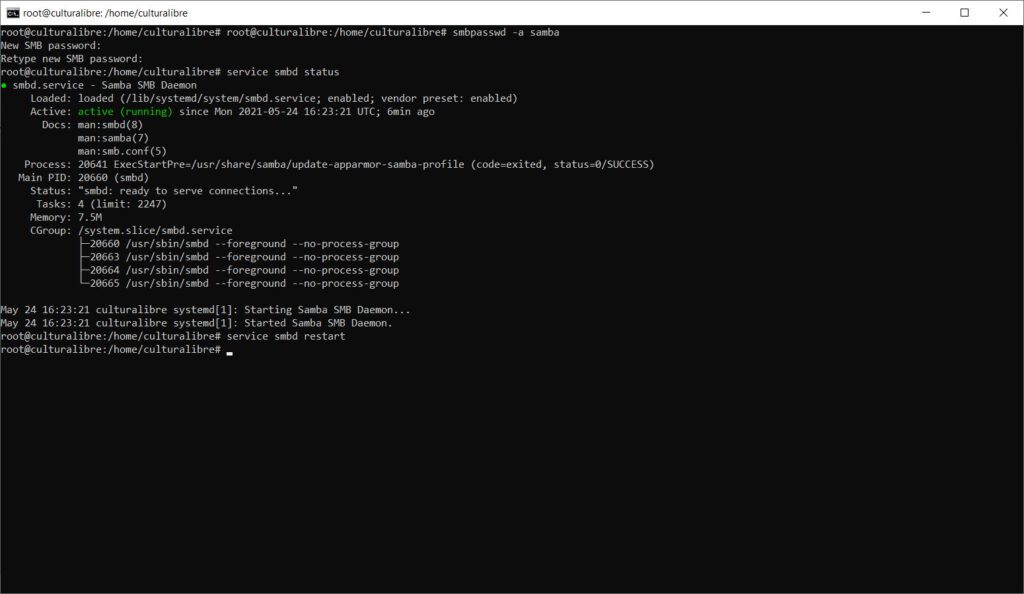
smbpasswd -a samba
Al hacer lo anterior, te pedirá que ingreses una clave de usuario de Samba; asimismo, puedes ver en todo momento el estado del servicio Samba en tu computadora tecleando el comando:
sudo service smbd status
…o bien, puedes reiniciar el servicio ejecutando el siguiente comando también:
sudo service smbd restart
¿Cómo conectarte a tu servidor de archivos Samba desde Windows?
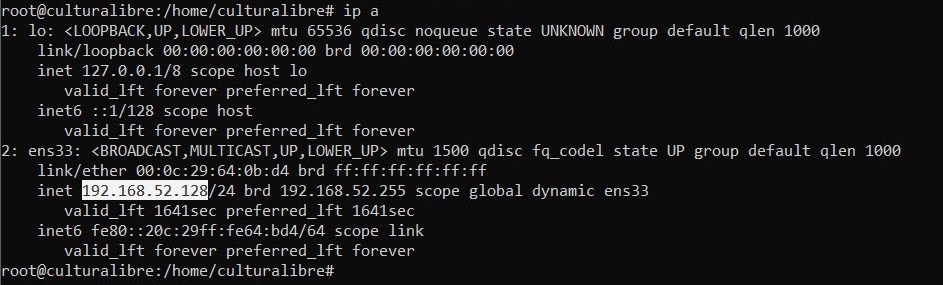
Si has seguido los pasos anteriores, tu servidor Samba está listo para funcionar; para acceder al mismo desde Windows, lo primero que tienes que saber es la IP que tiene asignada dentro de tu red de área local. Para ello, ejecuta el comando IP en Linux:
ip a
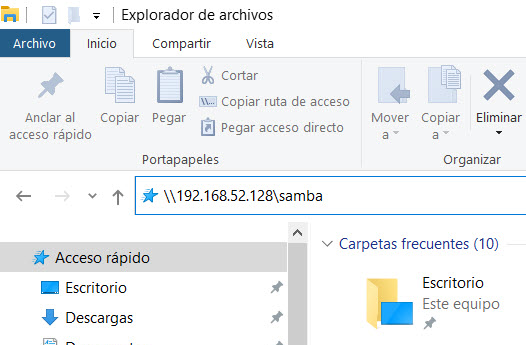
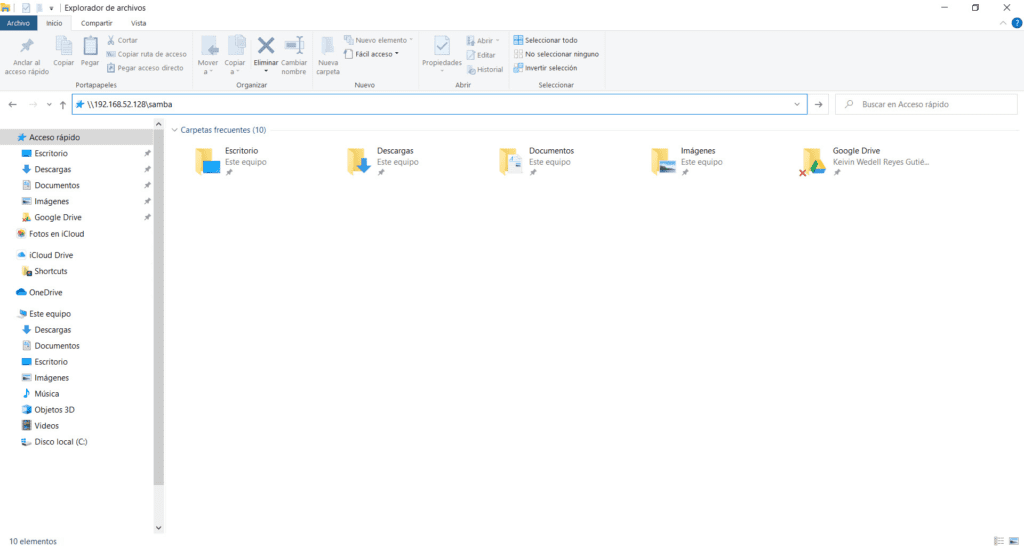
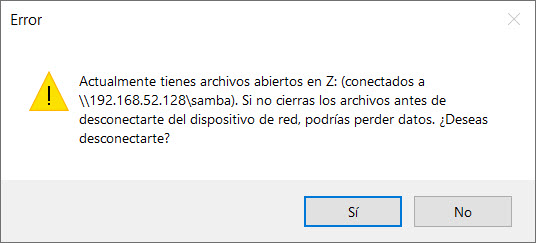
En el caso del presente ejemplo, la IP que tiene mi computadora con Samba es la 192.168.52.128; así, solo tienes que abrir una ventana del Explorador de Windows y teclear algo como sigue y presionar Enter:
\\192.168.52.128\samba
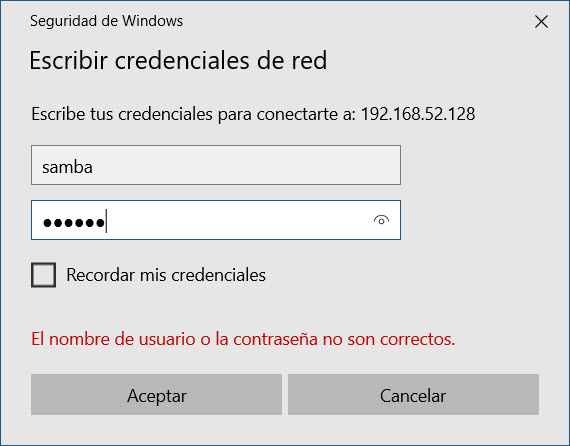
Es muy importante que utilices la diagonal invertida; en tu teclado, la puedes obtener presionando la tecla ALT DERECHA + la tecla ? (la que está justo a la derecha del cero). Si todo ha resultado correcto, inmediatamente se te desplegará un cuadro de información como el que sigue:
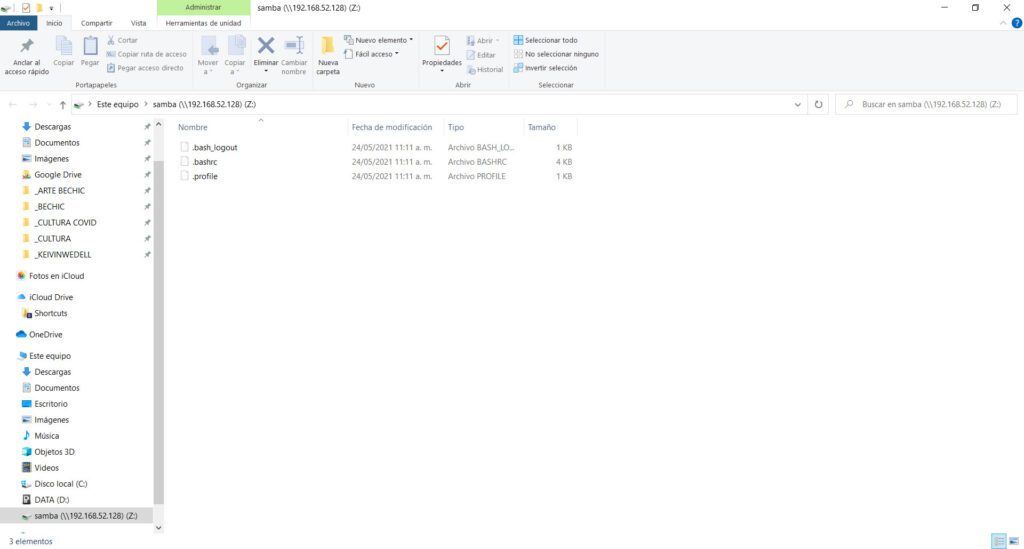
Aquí, solo resta ingresar el nombre de usuario y contraseña que configuraste al inicio, y activar la opción “recordar credenciales”, si así lo deseas, para evitar tener que teclearla en cada ocasión que desees acceder. Con esto, ¡ya tienes listo tu servidor Samba para almacenar archivos!
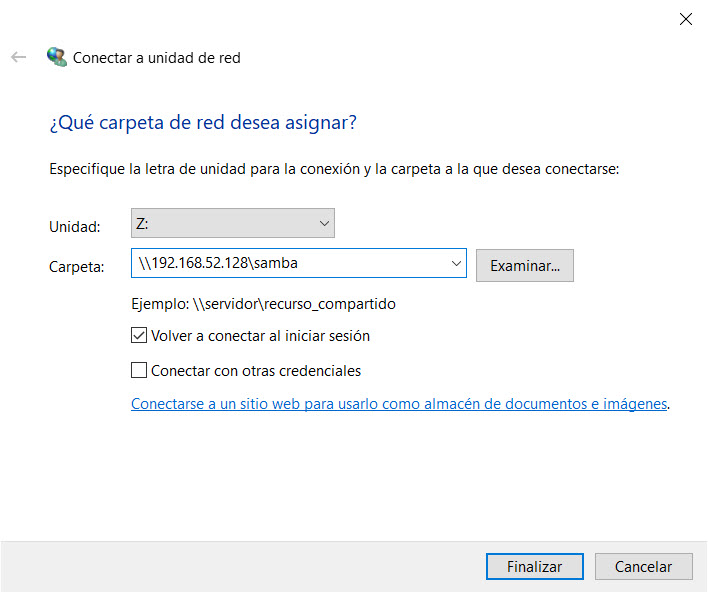
Añadir tu servidor Samba como una unidad de disco de red
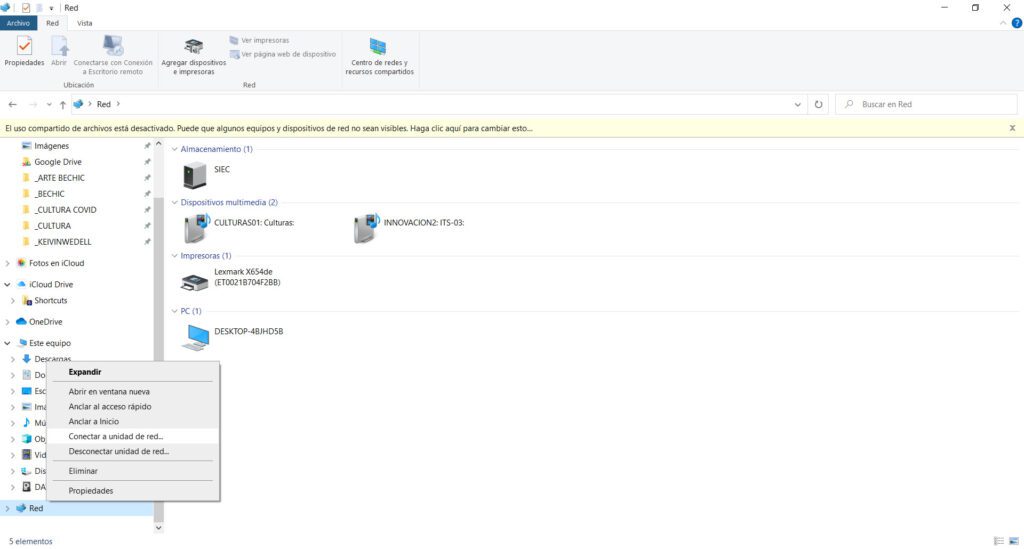
Hasta el paso anterior, tenemos un servidor Samba funcional. No obstante, resulta ser muy cool el poder añadir mi servidor de archivos como “una unidad de red” en mi explorador en Windows.
Para hacer esto, es muy fácil: con una ventana del explorador de archivos abierta, haz clic con el botón derecho del mouse sobre el icono “Red” y selecciona la opción “Conectar a una unidad de red”.
Acto seguido, Windows te solicitará que asignes una letra a tu “nueva” unidad de disco, así como la ruta de acceso al “recurso compartido”. Para ello, deberás ingresar la IP y nombre de usuario de tu servidor Samba; en mi caso:
Unidad: Z:
Carpeta: \\192.168.52.128\samba
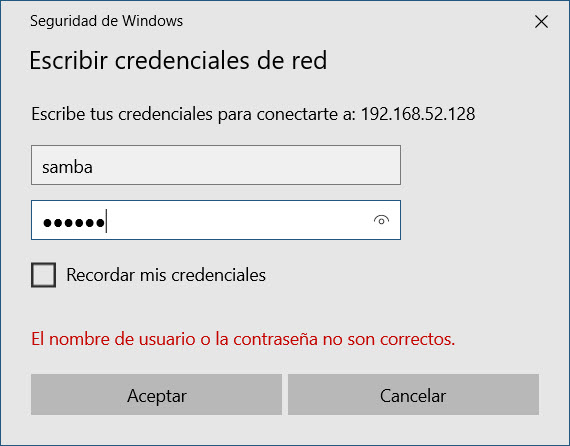
¡Y listo! Sólo deberás teclear nuevamente tu nombre de usuario
y contraseña creados en cada ocasión que desees acceder si es que no activaste la opción “Recordar credenciales”.
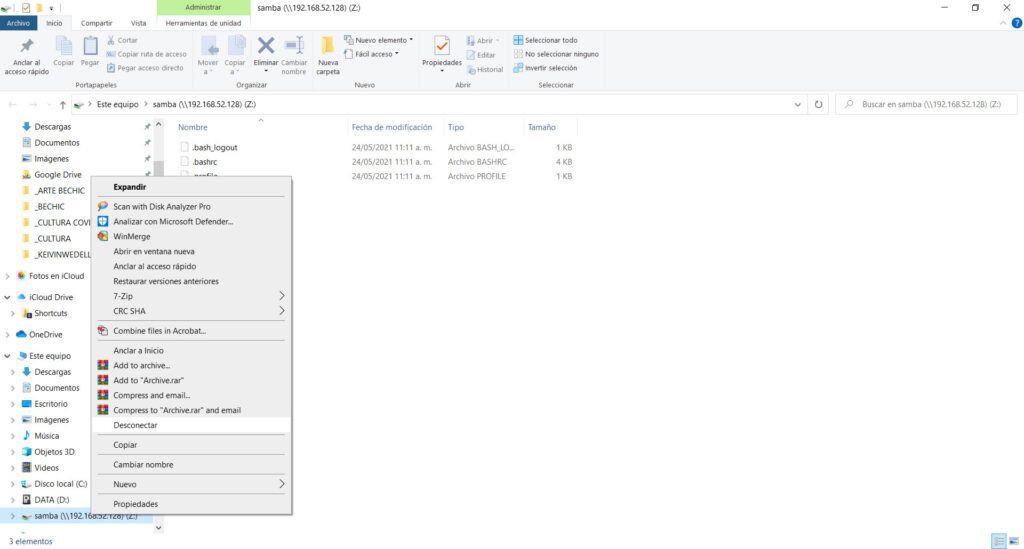
Si en algún momento deseas desconectar tu red, solo presiona botón derecho sobre una unidad de red existente, y selecciona la opción “Desconectar”.
Precioso cortometraje escrito y dirigido por Chris Milk en el año 2009 el cual fue producido para los 42 Second Dream Film Festival realizado en Beijing, China. Deseo que lo disfrutes:
Tengo una Laptop Lenovo Legion Y720 desde la cual realizo tareas de diseño, edición de video y trabajo con la web desde 2 sistemas operativos distintos. En GNU/Linux Ubuntu 20.04 LTS todo funciona bien, pero en Windows 10 no por lo que me di a la tarea de solucionar error en menú contextual mediante una pulsación con dos dedos (tap two fingers) me resulta indispensable en entornos gráficos.
Cuando la compré, noté que la función de mostrar el menú contextual (clic con el botón derecho del mouse) utilizando un “tap” a dos dedos (tap two finger) no funcionaba en Windows 10 pero en GNU/Linux sí.
Con ello, me dí a la tarea de buscar e instalar drivers originales, asignar valores de fábrica, mover configuraciones en el Panel de Control en Windows en donde, a pesar de que las configuraciones debían de resolver la posibilidad de obtener el menú contextual a 2 dedos, no lo hacían.
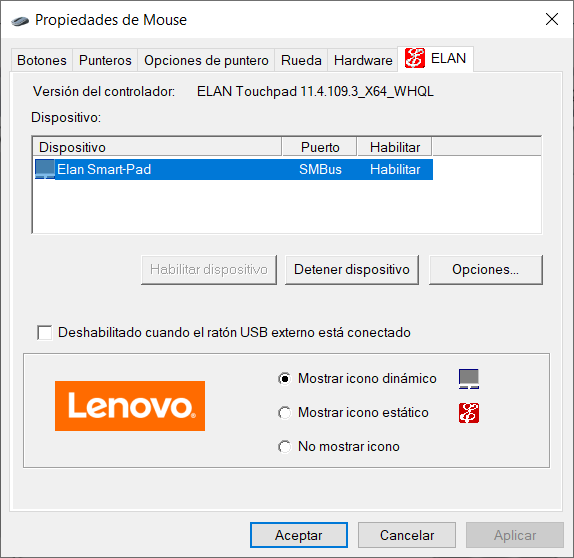
Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.
No obstante, al acceder a las configuraciones de Elan, en apartado “Varios dedos”, aún y cuando tengas la configuración del “Clic” a “Dos dedos” activada, el menú contextual no funciona; no importa si lo activas o desactivas múltiples veces: lo único que hace es poner el valor de 7 a Tap_Two_Finger y dejar en blanco otros valores del registro de Windows. Por ello, te ofrezco la solución más abajo.
Solucionar error en menú contextual para activar tap two fingers en una Lenovo Legion Y720
Revisando en un foro y otro, así como experimentando y comparando valores en el Registro de Windows, por fin pude dar con la solución; si tienes una computadora Lenovo Legion Y720 y no puedes obtener el menú contextual con 2 dedos, esto es lo que tienes que hacer:
Presiona la combinación de tecla Windows + R
Escribe “regedit” y presiona enter
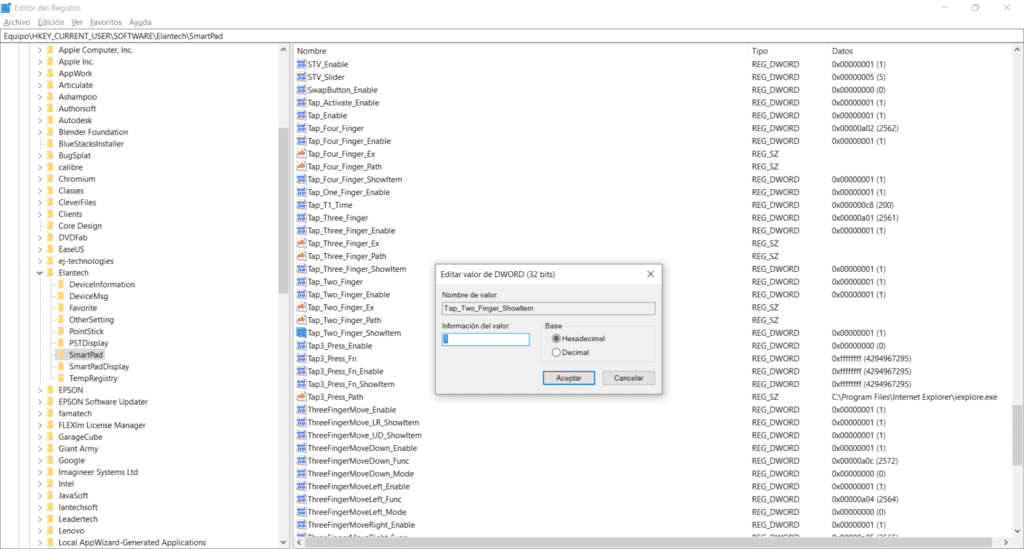
Busca / dirígete a la siguiente clave de registro: HKEY_CURRENT_USER\SOFTWARE\Elantech\SmartPad
Abrimos el editor del registro de Windows
Ahora bien, una vez dentro de la carpeta SmartPad, haz doble clic sobre los siguientes registros y asígnales el valor de 1:
Tap_Two_Finger
Tap_Two_Finger_Enable
Tap_Two_Finger_ShowItem
Aquí podrás encontrar los registros a modificar para corregir el menú contextual en tu laptop Lenovo Legion Y720
Hecho lo anterior, solo tienes que reiniciar tu computadora, y el tap con dos dedos debería ya de funcionar. ¡Espero que te haya servido!
Me he animado a elaborar este reporte de vulnerabilidad en router Huawei HG8245H de TotalPlay debido a que en días pasados, unos amigos resultaron víctimas de un fraude bancario por Internet debido a esta “falla” en el servicio que te voy a documentar. Pero primero, veamos algunos conceptos:
¿Qué es el Phishing?
El Phishing, es el conjunto de “técnicas” o “prácticas” basadas en el engaño a una víctima ganándose su confianza, haciéndose pasar por una persona, empresa o servicio de confianza (suplantación de identidad de tercero de confianza), para manipularla y hacer que realice acciones que no debería realizar (por ejemplo revelar información confidencial o hacer click en un enlace).
Para realizar el engaño, habitualmente hace uso de la “ingeniería social” explotando los “instintos sociales” de la gente y su “familiaridad” con actividades rutinarias que realiza por costumbre, como puede ser el ayudar o tratar de ser eficiente.
No obstante lo anterior, a veces también hace uso de procedimientos informáticos que aprovechan vulnerabilidades de software o hardware, lo cual implica conocimientos técnicos más complejos.
En casi todos los casos, el objetivo del Phishing es robar información pero, en otros, el propósito es instalar malware, sabotear sistemas o robar dinero a través de fraudes más organizados.
¿Cuál es el problema con el router Huawei HG8245H de TotalPlay?
Básicamente, te he de contar que, la “Empresa “, contrató un servicio de Internet Empresarial de TotalPlay 200, para lo cual les fue proporcionado un router Huawei HG8245H.
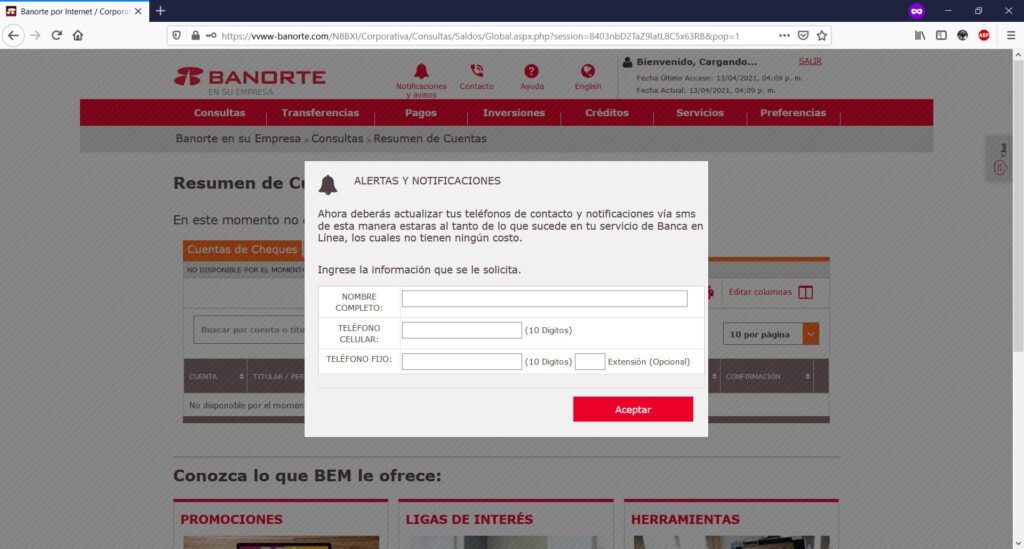
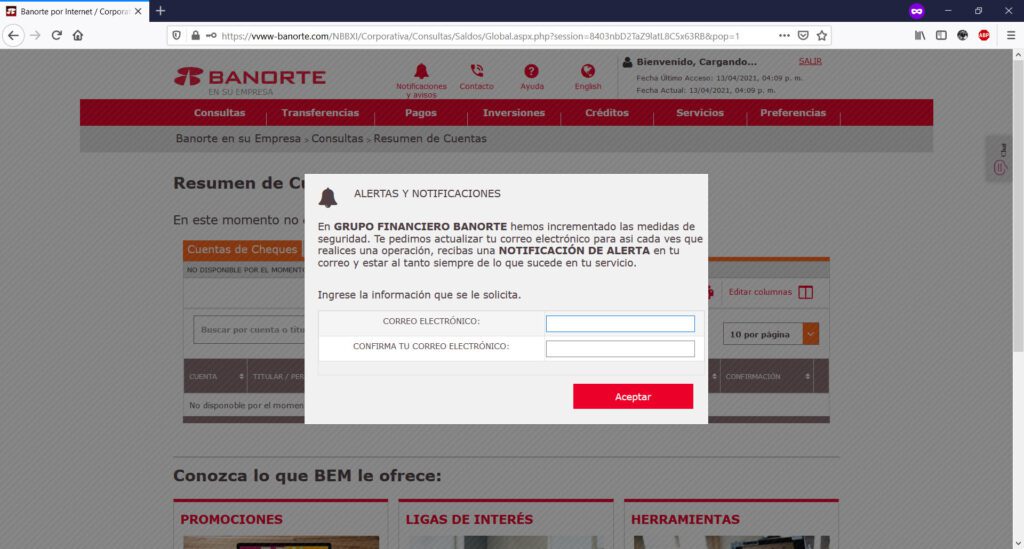
Este dispositivo, por defecto, venía con el puerto 23 habilitado (lo descubrimos después); en este contexto, una necesidad de la organización es la de permitir conexiones en el puerto 80 para dar “salida” a un servidor Web. Así, tanto el puerto 23 como el 80 están “abiertos”.
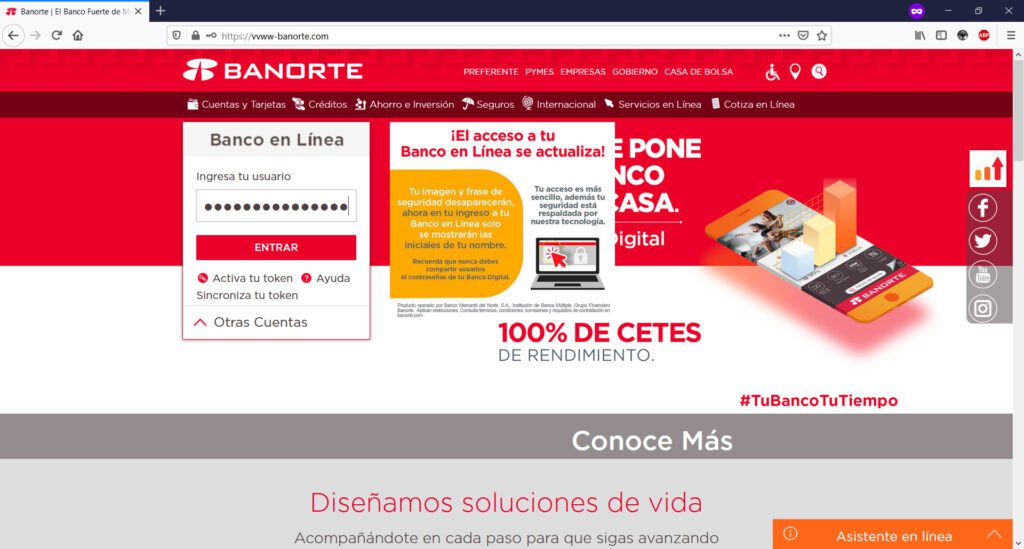
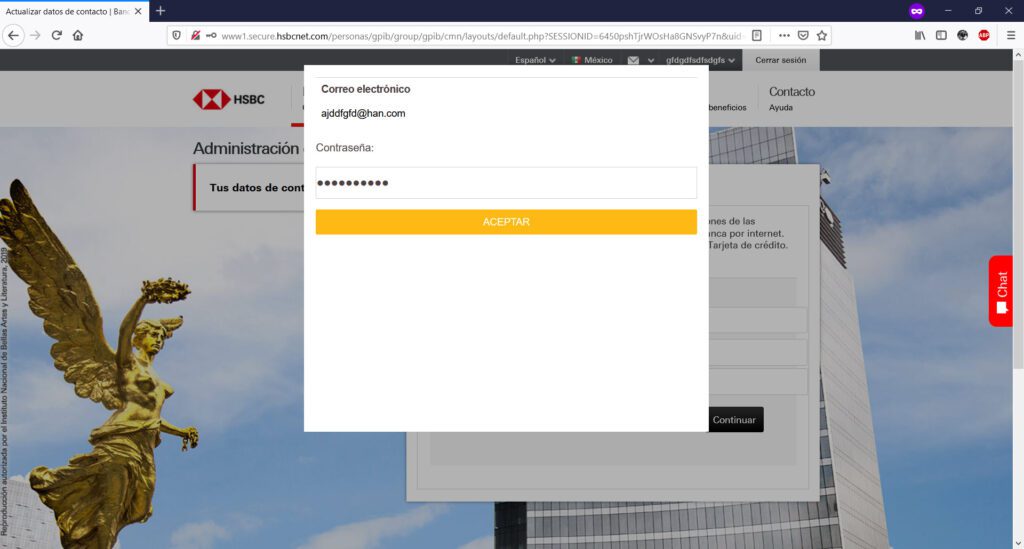
Ahora bien, en esta organización, se comenzaron a presentar redireccionamientos extraños de nombres de dominio de instituciones bancarias, mostrando de manera inicial un mensaje de error, certificados SSL inválidos, y necesidad de “realizar acciones adicionales” y permisos en el navegador para poder “visitar” el sitio web deseado, como por ejemplo, “aceptar” ir a la “Configuración avanzada” y “permitir” alguna excepción o riesgo de uso del certificado SSL para “conectar” con la institución bancaria.
En este sentido, si “aceptamos” continuar bajo nuestro propio riesgo, habremos abierto la posibilidad de que el sitio original de nuestra institución bancaria, sea “resuelta” en un servidor apócrifo que contiene una página clonada de mi banco, cuyo principal objetivo será el obtener claves, números de tarjeta, tokens, información personal, etc.
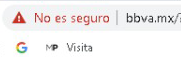
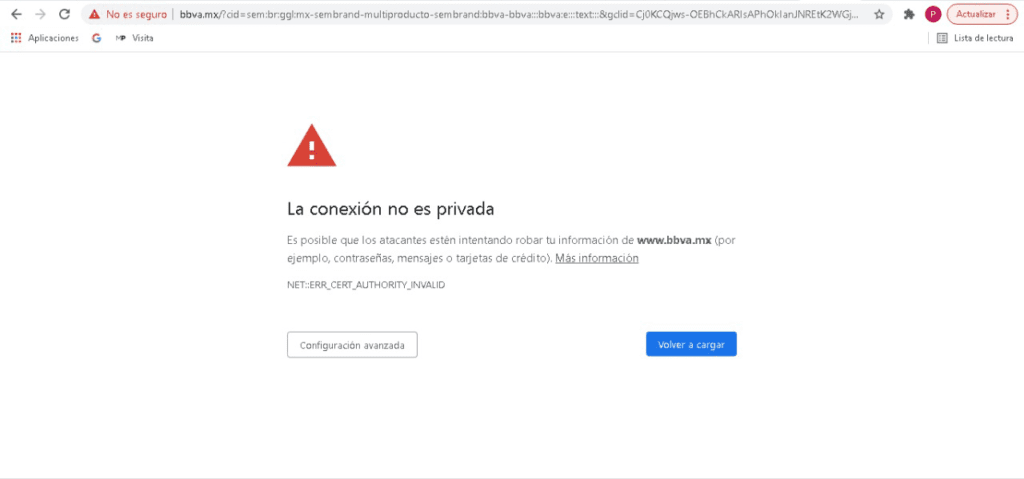
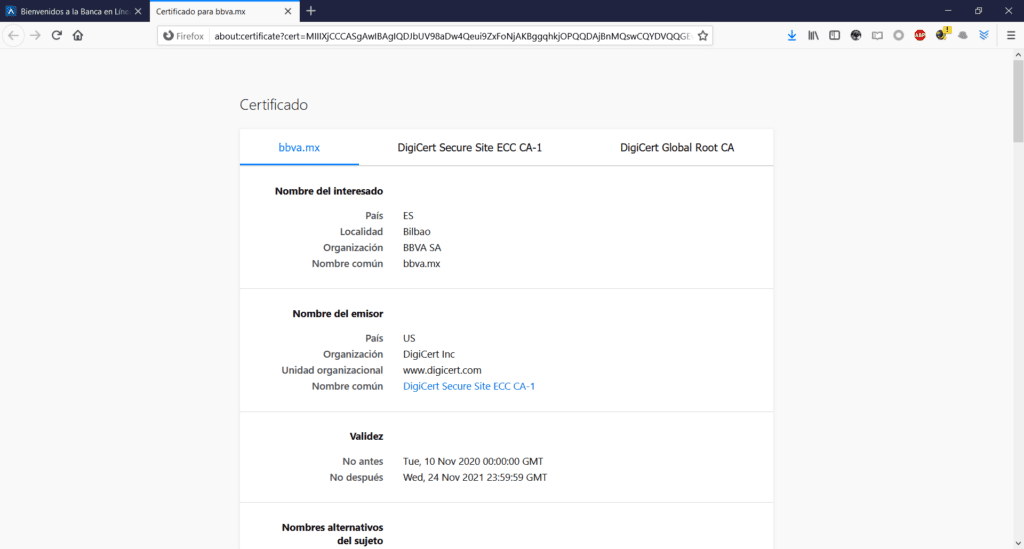
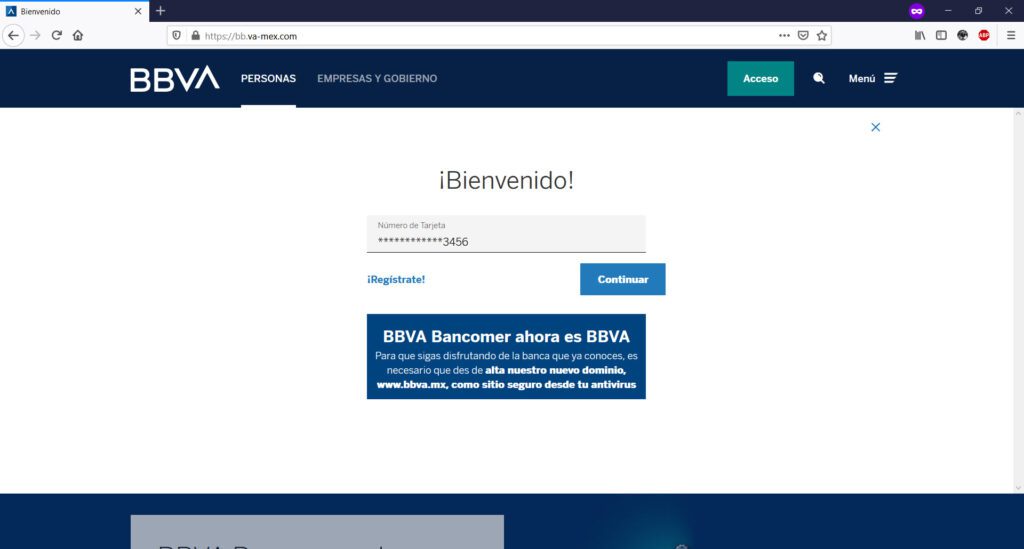
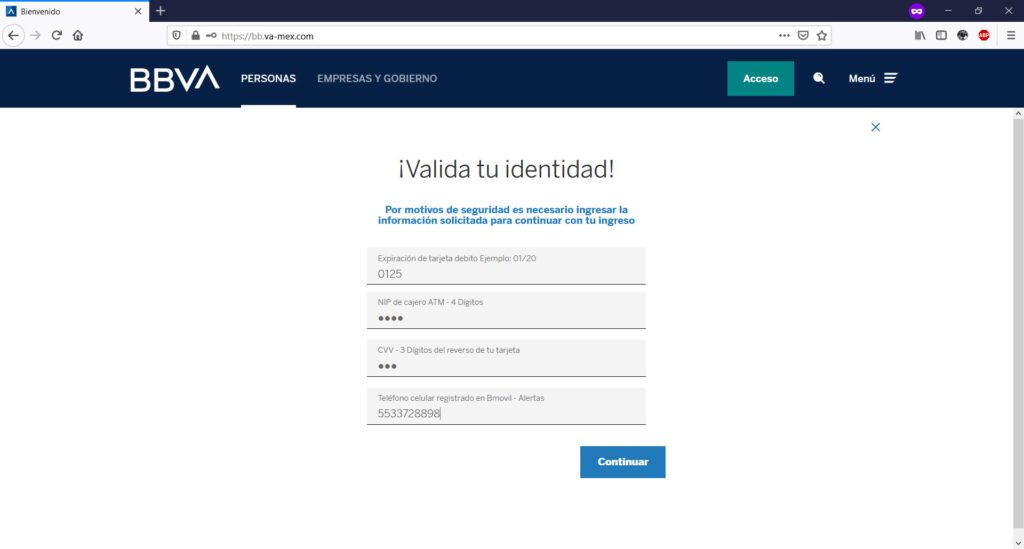
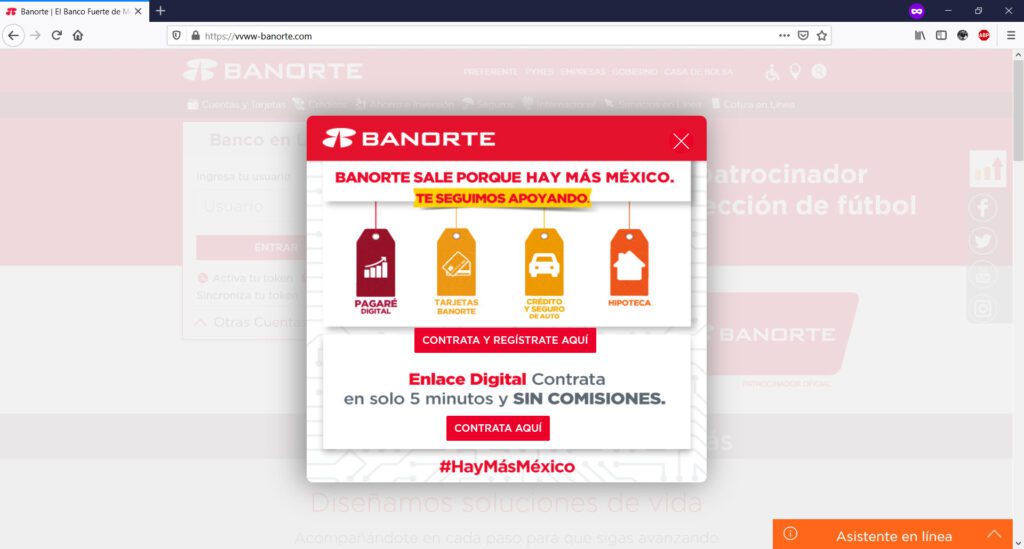
Si observas detenidamente la URL de mi captura de pantalla, podrás observar que la URL de la institución bancaria BBVA.MX ha sido “redireccionada” indebidamente a otro nombre de dominio: el sitio fraudulento, Phishing a la vista.
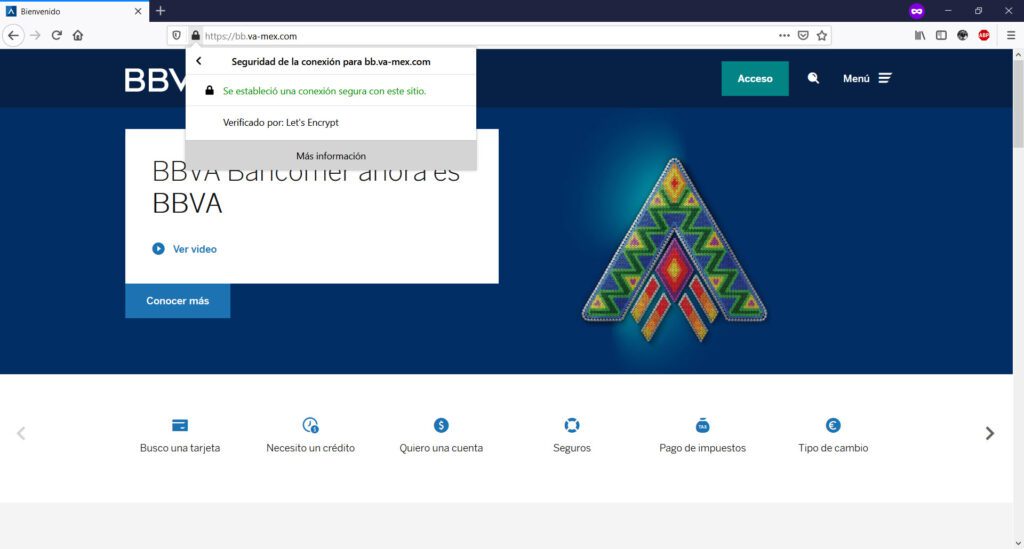
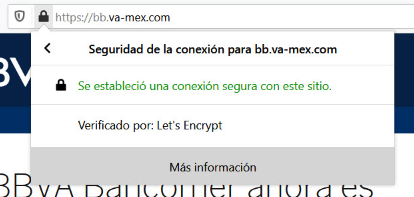
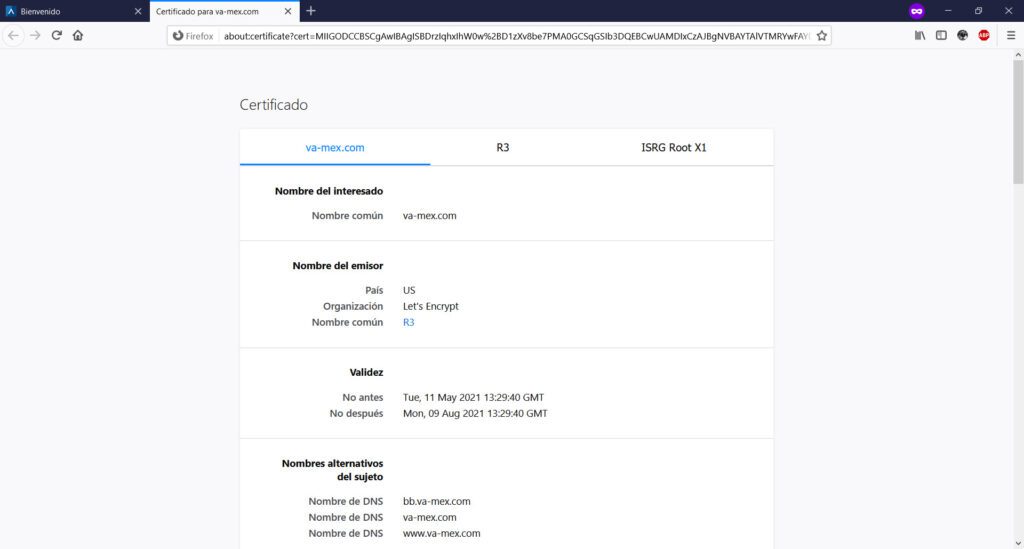
Inclusive, te “presenta” un certificado de seguridad SSL para darte la confianza de que estás navegando en un entorno “segura” aprovechando las firmas de Let´s Encrypt, un estupendo servicio gratuito que ayuda a los desarrolladores o administradores de sistemas a fortalecer la entrega de servicios web cifrados para proveer a nuestros usuarios de un cierto nivel de protección en la red; pero que en este caso, es utilizado maliciosamente para “dar la impresión” de que estamos en un sitio seguro. En sentido estricto, la conexión estará cifrada pero, el sitio web en cuestión tiene una motivación: robarte tus datos. Aquí puedes ver un certificado SSL de una URL fraudulenta o de Phishing…
…y aquí puede ver un certificado correctamente autenticado por una autoridad certificadora de una institución bancaria acreditada.
¿Por qué tiene este redireccionamiento mi router Huawei HG8245H de TotalPlay?
Si eres un usuario no técnico, debes saber que cualquier dispositivo que sirva para “proveerte” de Internet en tu oficina o domicilio, cuenta con un panel de administración para realizar configuraciones adicionales.
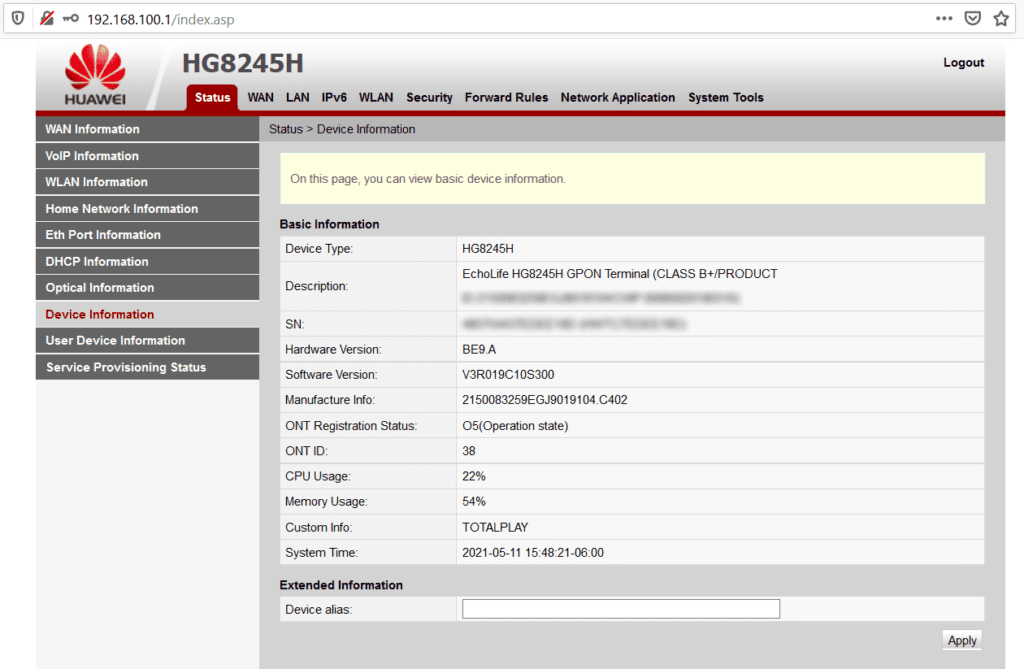
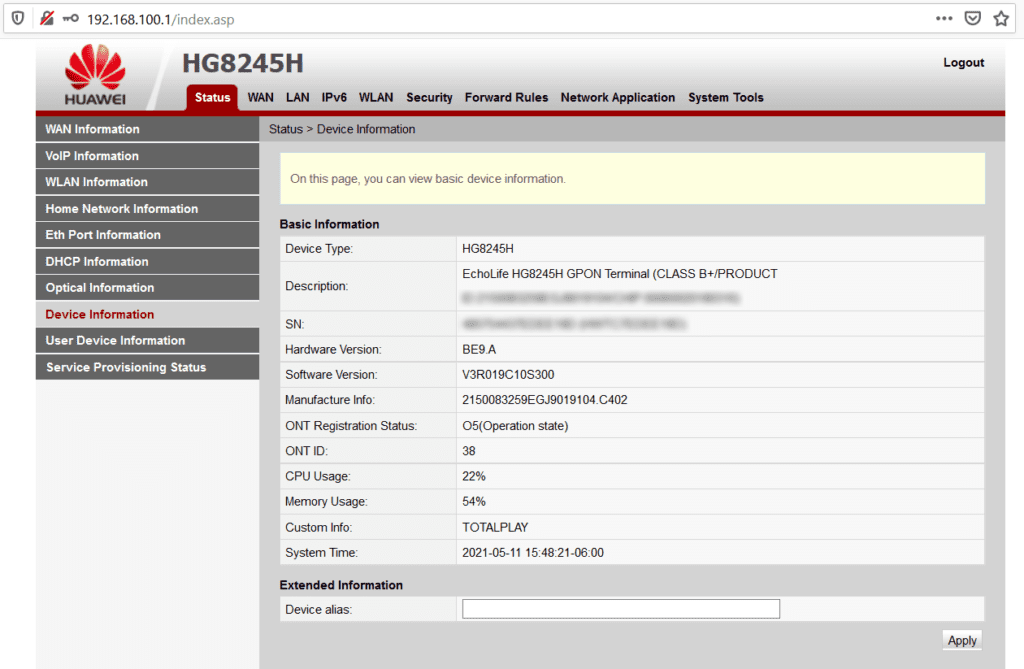
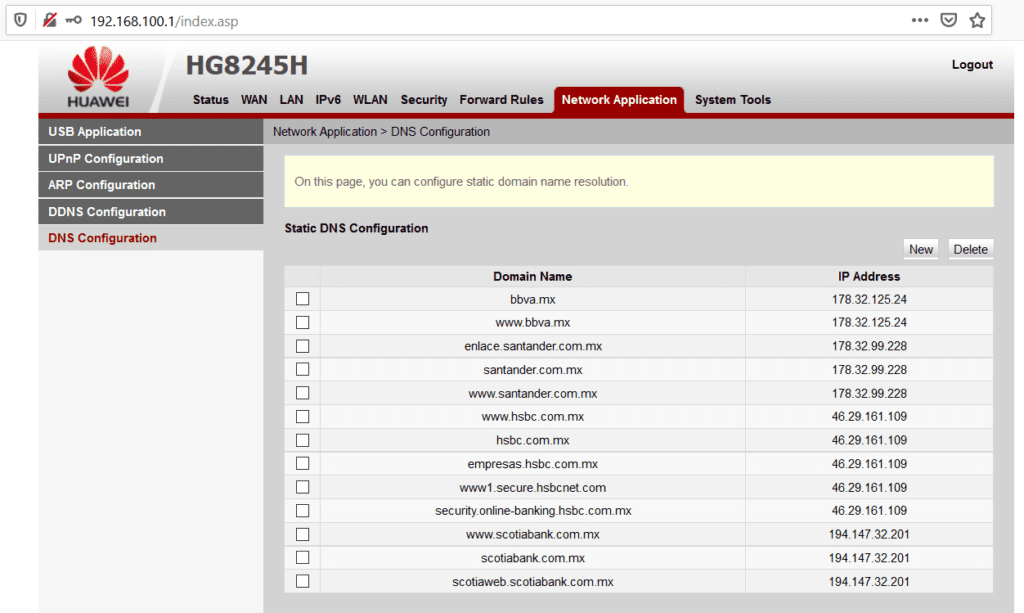
En este sentido, el router Huawei HG8245H de TotalPlay, una vez que te hayas conectado de manera alámbrica o inalámbrica al mismo, puede administrarse accediendo a la IP 192.168.100.1 desde tu navegador.
Un primer problema es que, de fábrica, viene configurado para su acceso con los siguientes datos:
Usuario: root
Password: admin
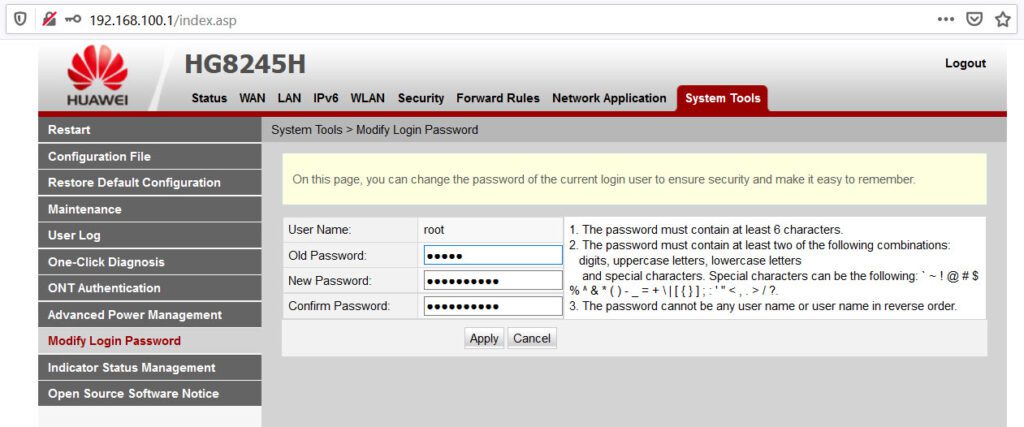
Así, empleando estos datos, alguien dentro de tu red podría “aprovecharse” del dispositivo y realizar configuraciones indebidas. Aquí, puedes ver una captura de pantalla del panel de administración del router.
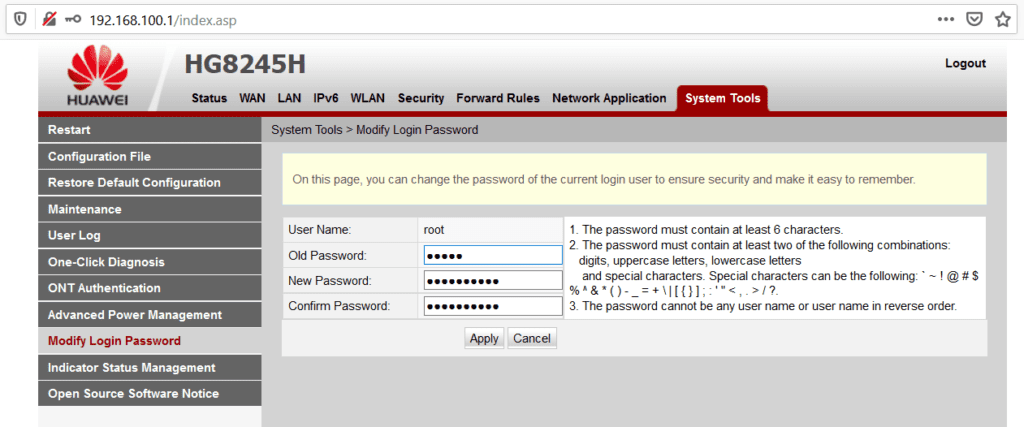
Una buena práctica para “dificultar” el acceso no autorizado al dispositivo es cambiar la contraseña de administración. Esto puede hacerse fácilmente accediendo a la pestaña “System Tools” y opción “Modify Login Password” para cambiar la contraseña.
En sentido estricto, si no cambias la contraseña de administración con la cual viene el router de fábrica, tienes una grave vulnerabilidad ahí que puede explotar, teóricamente, un usuario mal intencionado que esté conectado a tu red interna.
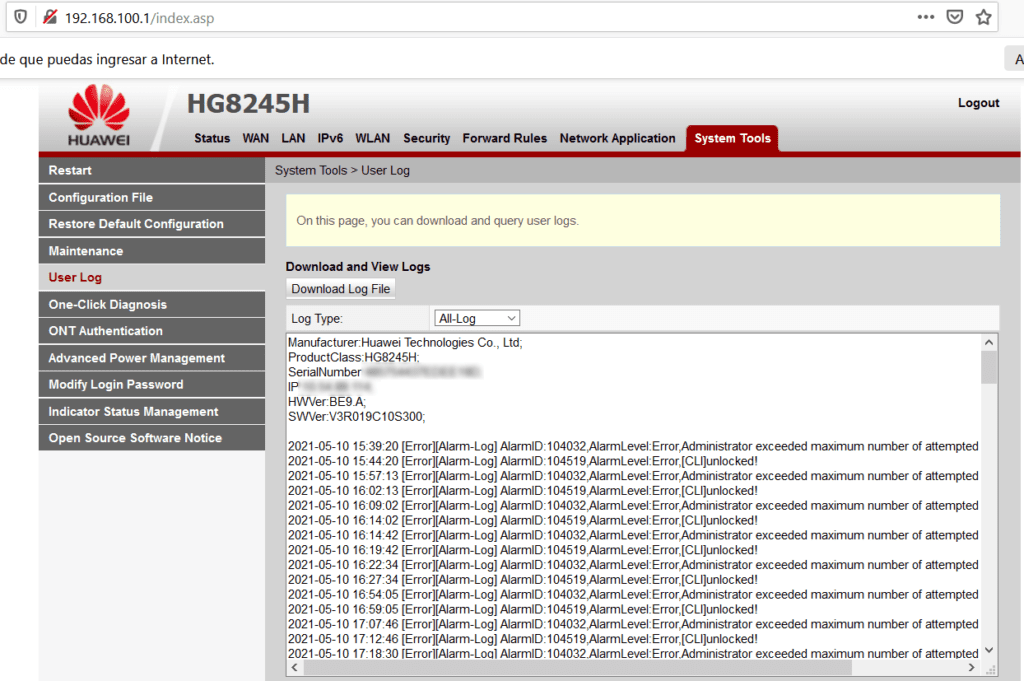
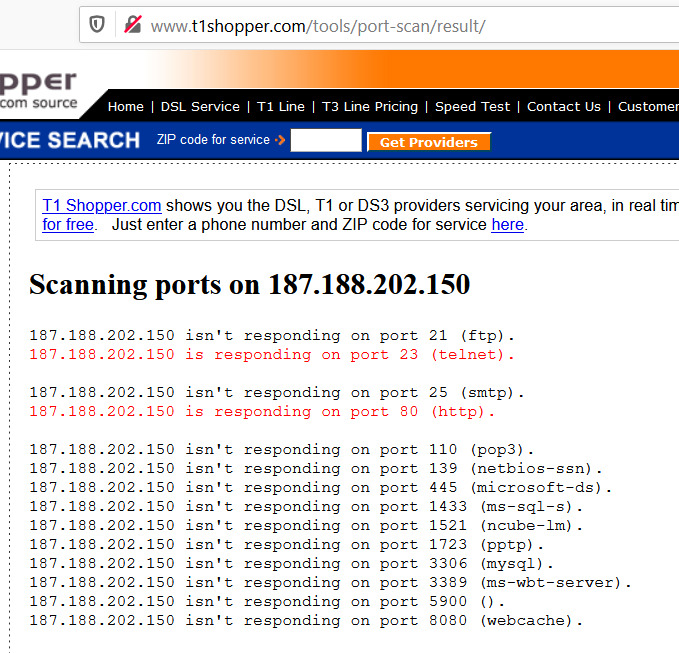
No obstante lo anterior, me ha pasado que, a pesar de que cambie la contraseña de acceso al dispositivo, inexplicablemente es vulnerado en sus configuraciones. Aquí, tengo mis sospechas sobre el puerto 23 que permite conexiones mediante Telnet que me ha dejado abierto TotalPlay por razones que desconozco.
Además, estas sospechas sobre el puerto 23 se incrementan en el sentido de que, revisando registros de acceso al panel de administración mediante su portal Web, no muestra ninguna evidencia de acceso no autorizado a través del mismo, pero sí intentos recurrentes de acceso al dispositivo.
La manipulación de nombres de dominio mediante configuración DNS en router Huawei HG8245H de TotalPlay
Y aquí llegamos al punto: el atacante malicioso (que me da la impresión, puede acceder desde la red interna de TotalPlay o bien, de mi propia red interna mediante algún equipo infectado con malware), “modifica” y “redirecciona” los destinos de “resolución” de un nombre de dominio, suplantando los registros DNS originales por otros que sin ningún inconveniente pueden ser “resueltos” mediante redireccionamiento en un servidor que haya configurado e instalado para tal propósito. Te explico:
https://bbva.mx es el sitio web de un banco español que tiene operaciones en México; haciendo un ping simple desde una red no comprometida, está “apuntado” a la IP 23.3.212.126 para su correcto funcionamiento.
Sin embargo, nuestro atacante malicioso y mal intencionado, implementa configuraciones como estas para “apoderarse” de nuestra conexión y llevarnos a un sitio web clonado de esta institución bancaria. El módem ha sido intervenido para que el dominio BBVA.MX sea “resuelto” en una IP distinta a la IP legal (23.3.212.126) para robar nuestros datos e información bancaria.
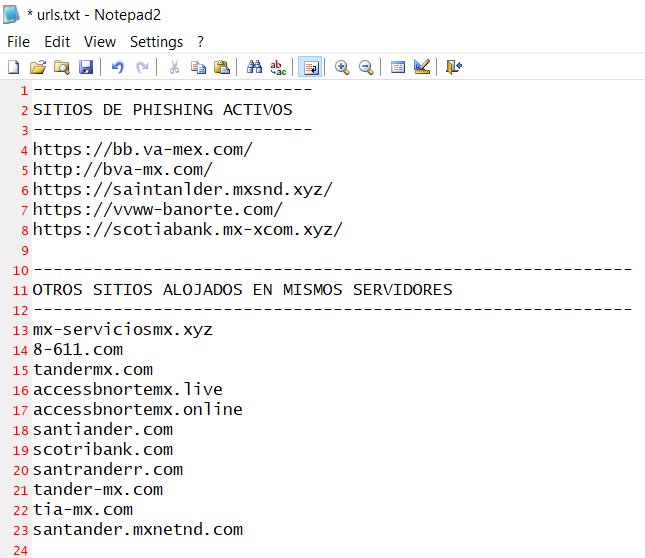
Como puedes observar en la captura de pantalla, los atacantes, han configurado la redirección de múltiples dominios de diversas instituciones bancarias para ser “resueltos” en servidores y dominios apócrifos, por ejemplo, aquí podrás ver una relación de sitios web de Phishing que he encontrado, y que están preparados para hacerse pasar por un banco y pedirte datos personales para robarte tu dinero:
¿Cómo te roban tus datos bancarios mediante técnicas de Phishing y vulnerabilidad en router Huawei HG8245H de TotalPlay?
Con la información que te he mostrado, y considerando un escenario en el que…
Tu router está intervenido y configurado con estos redireccionamientos.
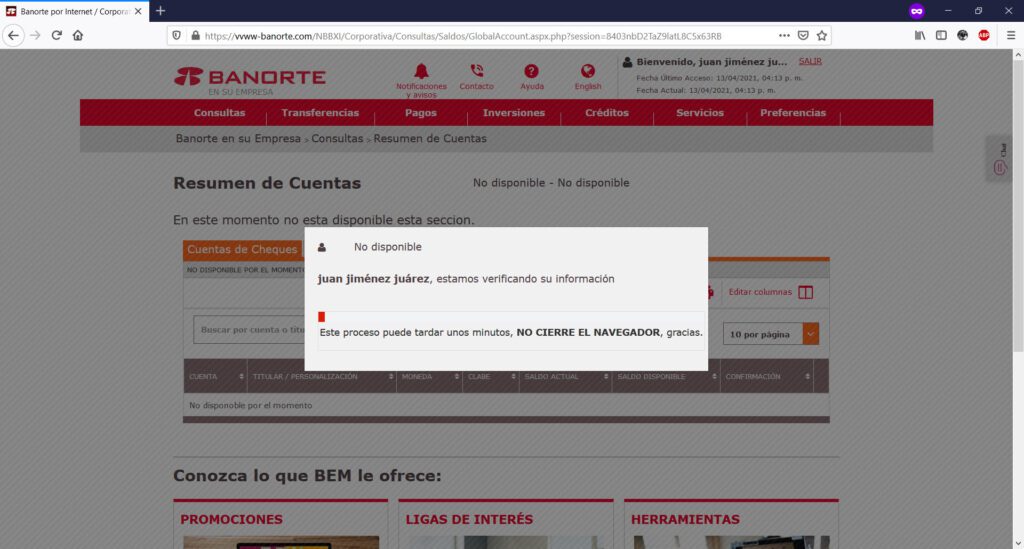
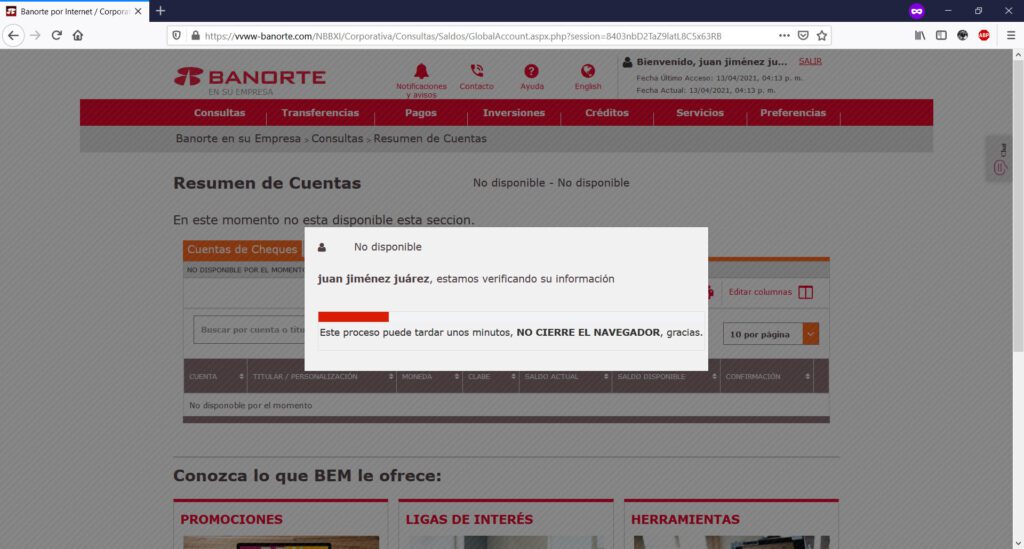
Intentaste entrar a tu banco y te mostró el navegador una alerta a la cual, diste tu autorización de que “aceptas el riesgo” y;
Te encuentras en un sitio web clonado (Phishing) de la lista anterior (pero puede haber muchos otros eh)…
…los maleantes, han conseguido una primera fase de su objetivo: ganar tu confianza en su sitio web. ¿Qué ocurrirá a continuación?
Básicamente, te encontrarás con algo como esto, siendo BBVA el caso de ejemplo de sitio web de phishing o clonado:
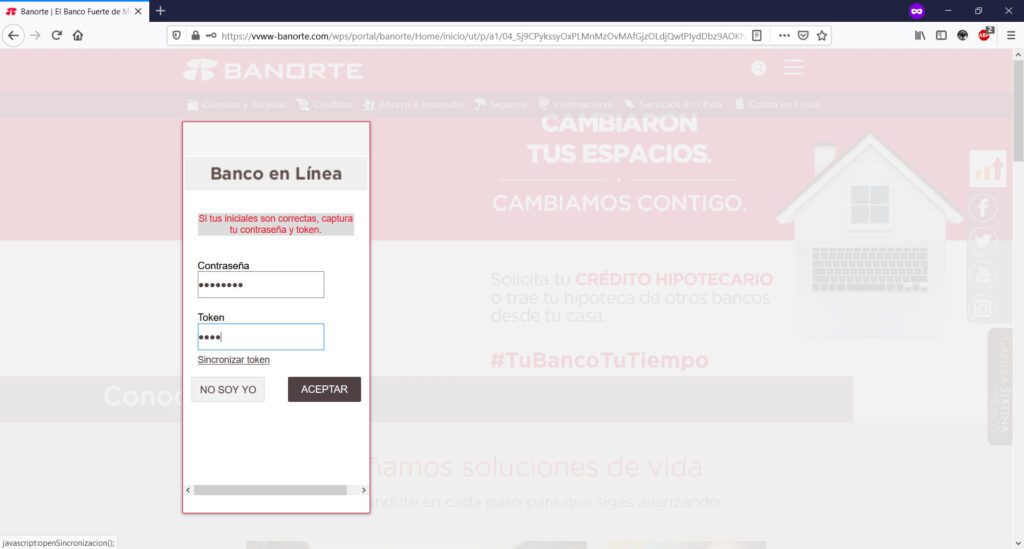
Te pedirán tu número de tarjeta de bancaria…
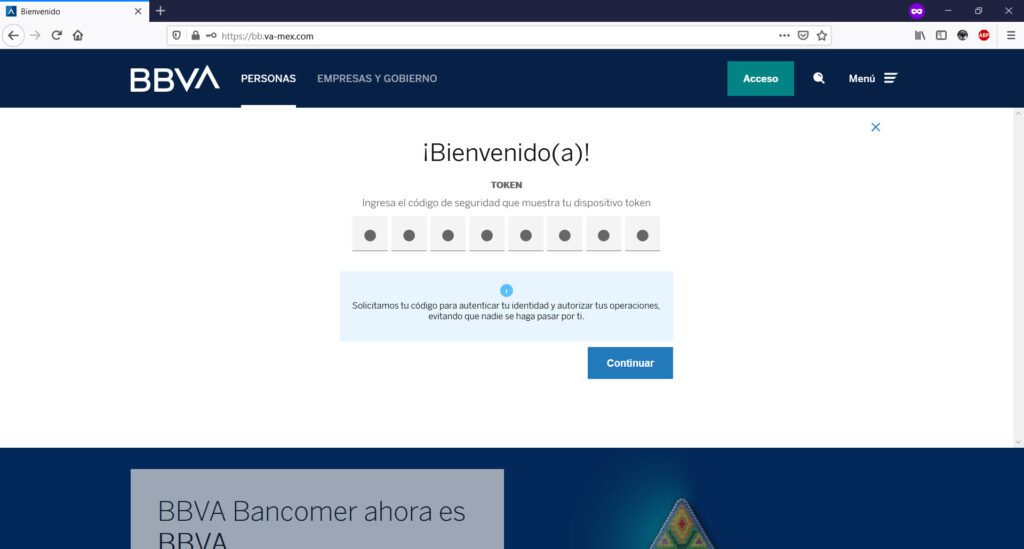
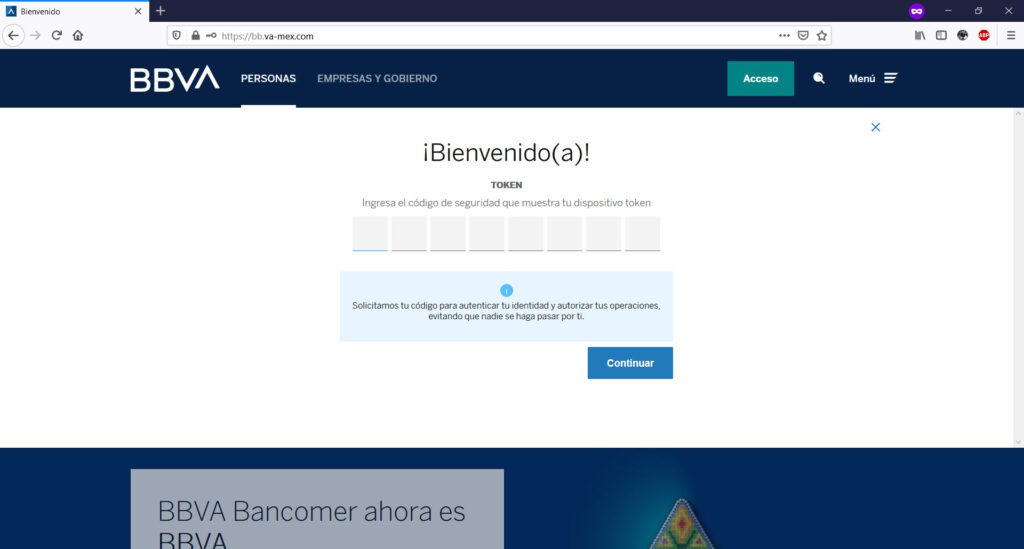
Te pedirán tu token de acceso (clave generada en tu app)…
Hasta este punto, todo parecerá “normal” ya que son los datos básicos que generalmente una institución bancaria te pide para la banca en línea. Sin embargo, en las siguientes imágenes, los atacantes maliciosos te comenzarán a pedir información personal que a su vez, ellos podrán utilizar para ingresar a tu banca en línea y tomar el control de tu dinero:
Aquí, han creado un formulario en el cual te piden, “para validar”, datos de tu tarjeta bancaria y de registro de usuario.
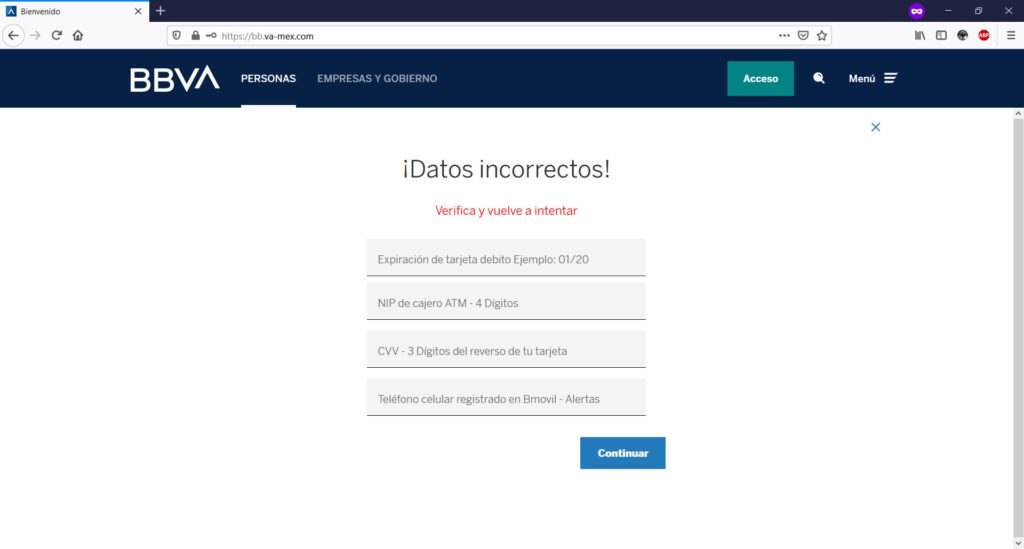
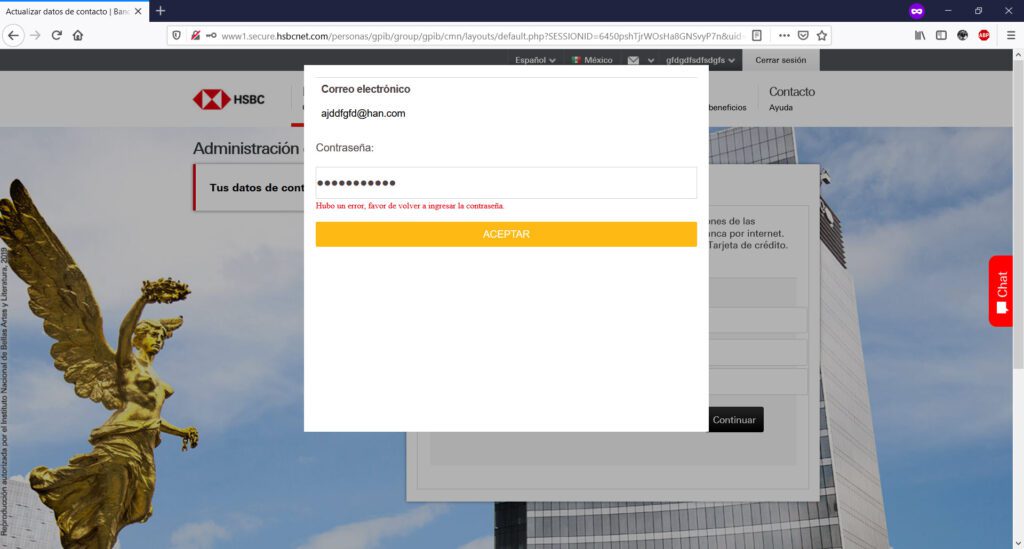
Cuando “envías tus datos para validar”, sean estos válidos o inválidos, te aparecerá una leyenda de “Datos incorrectos”; el objetivo de esto, es el de “engancharte” con la realización de múltiples intentos para que consigas tu objetivo (entrar a tu banca en línea) pero, explotando esta necesidad tuya “proporcionándoles” el mayor número de tokens o confirmación de datos bancarios posibles (una vez que “diste tus datos bancarios”, entre más “tokens” proveas, es para ellos mejor) a través de su sitio web clonado o de phishing que para tal propósito han creado.
Aquí, te vuelven a pedir que ingreses tu token en un “nuevo intento” por haber ingresado “datos incorrectos” a “tu banco” (sitio web de phishing o clonado)… y así será sucesivamente hasta que te canses.
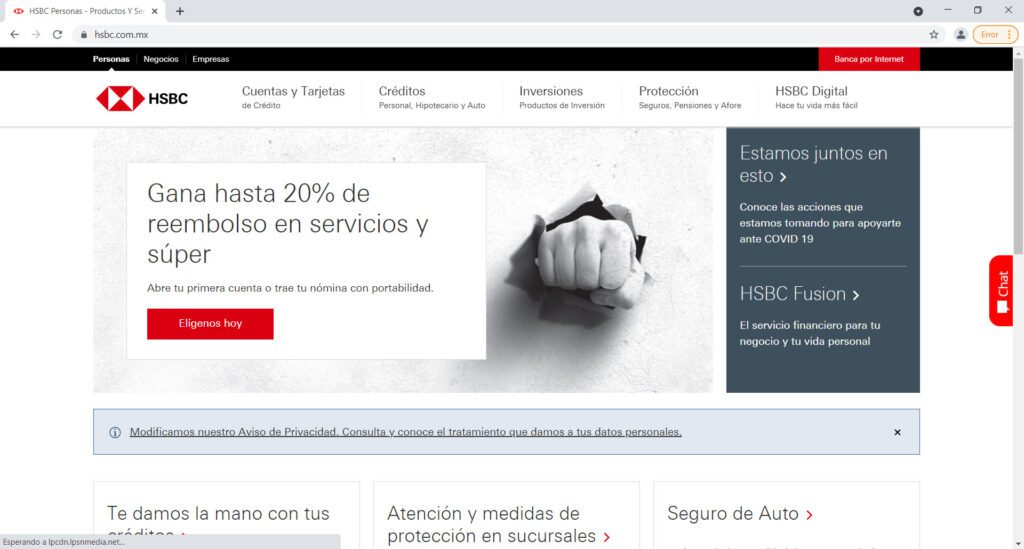
Un proceso similar al anterior ocurre con otros bancos, en los que realizan la clonación del mismo para implementar esos sitios web de phishing:
¿Cómo puedo protegerme del fraude bancario mediante esta técnica de phishing en router Huawei HG8245H de TotalPlay?
Tanto si eres usuario doméstico como administrador de red de una organización, lo principal es que:
1.- Resetees completeamente tu dispositivo a sus valores de fábrica y modifiques la contraseña de acceso del mismo, sobre todo si no puedes acceder a su panel de administración mediante la URL 192.168.100.1 con sus valores por defecto (usuario: root, pasword: admin) ya que, es muy probable que alguien te los haya cambiado.
Debes recordar que este router, solo permite cambiar contraseñas y no tiene forma de que se modifiquen sus nombres de usuario.
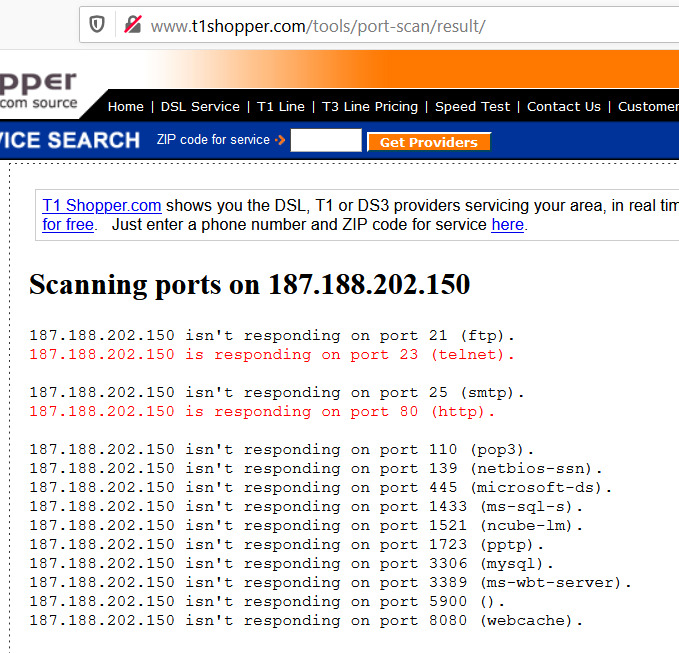
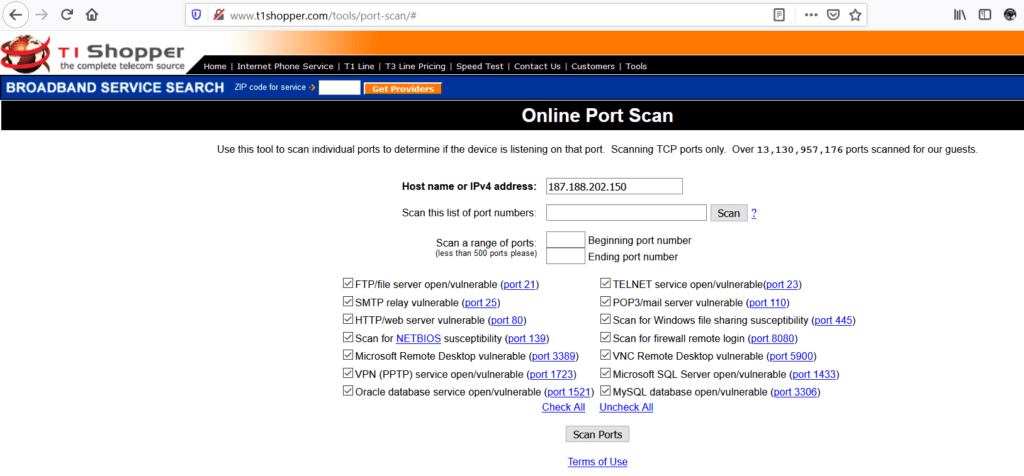
2.- Te asegures que tu dispositivo no tiene el puerto 23 abierto (si así te lo entregó el técnico de TotalPlay, me queda aún más la duda de si no es que hay personal dentro de la empresa entregando dispositivos configurados para ser vulnerados). Puedes realizar una prueba rápida así:
a) Investiga cuál es la IP pública de tu red; para ello, ingresa al sitio https://myip.es/, por ejemplo:
b) Una vez que tengas tu IP, ingresa a http://www.t1shopper.com/tools/port-scan/ y realicemos un escaneo rápido de puertos abiertos a tu dispositivo, no sin antes seleccionar “check all” para que se realicen pruebas en los puertos más comunes.
Si te aparece el puerto 23 abierto, es muy probable que tu dispositivo esté intervenido y vulnerable; en los resultados del escaneo, te estaría apareciendo algo así:
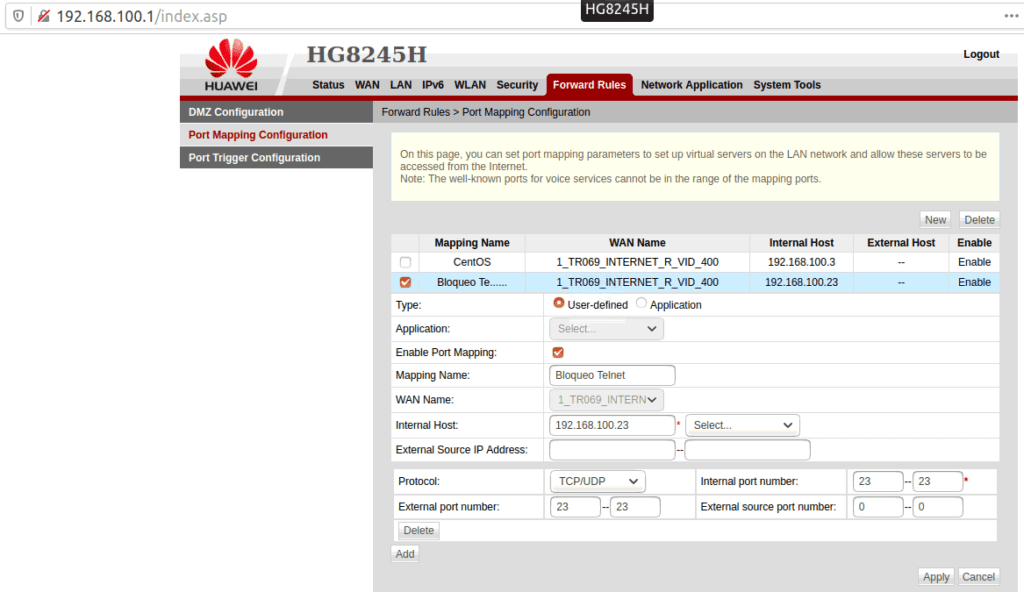
3.- Ya que tengas tu router Huawei HG8245H reseteado y con contraseña modificada, accede ahora al panel de control e ingresa al apartado “Forward Rules” y “Port Mapping Configuration”. A continuación crea una nueva regla (en “Mapping Name” ponle el nombre que desees) con los siguientes valores y haz clic en “Apply”:
Con lo anterior, ¡habrás aplicado una capa de seguridad a tu dispositivo para mitigar la vulnerabilidad en router Huawei HG8245H de TotalPlay.
Recomendaciones finales
Sin importar si eres un usuario doméstico o administrador de redes, espero que este artículo te haya servido.
En mi caso, una práctica que tengo por una Internet segura es el de notificar a ISPs, Google, Mozilla sobre la existencia de dominios con actividad maliciosa. No obstante, me he encontrado con la indiferencia de TotalPlay para resolver este tema (insisto nuevamente, me queda la impresión de que los “ataques” vienen de dentro de la red de ellos y no tanto de la red pública) así como también, el total desinterés de los bancos para responder a los llamados y dar protección a sus usuarios.
Por ello, te invito a que pongas atención en las siguientes recomendaciones.
Denuncia las URLs maliciosas siempre; en tu navegador Google Chrome haz clic en los “3 puntitos” de opciones adicionales, selecciona el menú “ayuda” y envía tu reporte con comentarios (importante que pongas “sitio de phishing”) haciend clic en “enviar reporte”; en el navegador Mozilla Firefox, haz clic en las “3 rayitas” de opciones adicionales, haz clic en el menú “ayuda” y envía también tu reporte haciendo clic en la opción “Reportar sitio fraudulento…”
Ten la buena práctica y costumbre de siempre verificar la validez de las URLs que visitas.
Enseña a tus usuarios y compañeros a navegar de manera segura.
Cambia tu router por otro mejor; los TP-Link Archer AX50, es un estupendísimo dispositivo que tiene una solución embebida para proteger a todos los usuarios de tu red de virus y bloquear URLs fraudulentas o de phishing. Si instalas Internet de TotalPlay, no te fíes de su router: compra y configúrate el Archer AX50 para que tengas mayor confianza y seguridad en tu red, sobre todo si vas a utilizar tu conexión para dar internet a tus empleados, cubrir tus oficinas, realizar tus operaciones bancarias, etc. Invierte en tecnología, en infraestructura, en asesoría de los expertos.
En mi oficina, tengo una vieja laptop a la cual, el monitor de cuando en cuando deja de funcionar sin forma de volver a encenderlo nuevamente. Con ello en consideración, decidí tomar esta laptop para configurarme un modesto servidor conUbuntu Server 14.04 LTS en el cual tengo habilitado Apache, PHP y MySQL principalmente con la cual te mostraré cómo conigurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu.
Es pertinente comentar en este que punto que para el presente tutorial, procedí a realizar una instalación limpia de Ubuntu Server 14.04, configuré mi tarjeta de red, particiones y demás, pero al concluir el proceso de reinicio posterior a la instalación.
Así, para lograr que Ubuntu “inicie” y se “conecte” automáticamente a una red WPA, tenemos que seguir los siguientes pasos desde la consola o línea de comandos:
1.- Averiguamos en primer lugar el nombre de nuestra interface de red inalámbrica (generalmente es wlan0):
iwconfig
2.- Creamos el archivo de configuración del demonio de administración de redes wpa_supplicant…
sudo nano /etc/wpa_supplicant/wpa_supplicant.conf
…y guardamos dentro del mismo los siguientes valores:
5.- Pedimos ahora una dirección IP al servidor DHCP activo:
sudo dhclient wlan0
6.- Con ello, si hacemos un ping a google.com, deberías de obtener ya una respuesta. Pero bien, para que nuestra configuración se cargue en cada reinicio, abrimos el archivo /etc/network/interfaces…
sudo nano /etc/network/interfaces
…y nos aseguramos de añadir lo siguiente:
auto wlan0
iface wlan0 inet dhcp
wpa-ssid NOMBRE-DE-RED-WIFI
wpa-psk CONTRASEÑA-WIFI
7.- Para comprobar que el demonio wpa_supplicant se iniciará automáticamente en cada inicio del sistema, ejecutamos los siguientes comandos:









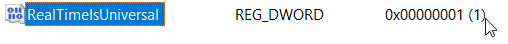




 Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.
Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.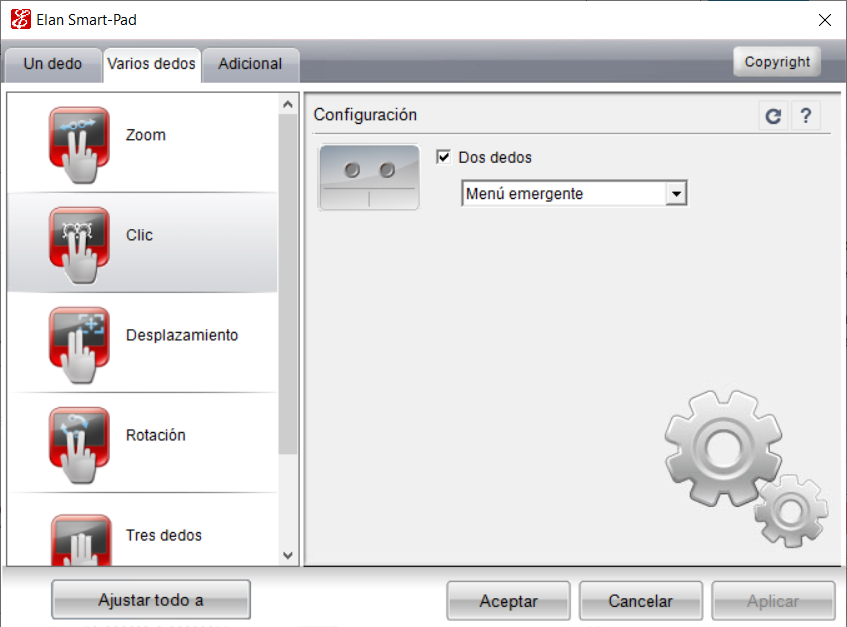






Debe estar conectado para enviar un comentario.